Compiler design 101
Since 240pm 7/13/2022
Lexeme - either a single character or a group of characters in the source code. Not just a group of more than 1 characters. They are the words of the program.
- Scanner - Reads the entire program. Turns 1 or more characters into lexical units or lexemes.
- Lexer - takes the lexemes and declares what category they should be under. The certain category is a token. The token is usually paired with a name and a value.
Lexers do not know nor care about the grammar of a sentence or the meaning of a text or program; all it knows about are the meaning of the words themselves. the compiler doesn’t know or have access to these “individual parts”. Rather, it has to first identify and find them, and then do the work of splitting apart the text into individual pieces.
spaces and punctuation divvy up the “words” of a sentence it always does two important things: it scans the code, and then it evaluates it.
Reads everything 1 character at a time. No matter how big the file is.
The simplest way of diving up a giant chunk of text is by reading it slowly and systematically, one character at a time. And this is exactly what the compiler does.
For each character that the scanner reads, it marks the line and the position of where that character was found in the source text.
Basically, lines are rows, character positions are columns
Positions
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
______________________________________________________________
0 X X X X X X N
1 T T T X X X X X X X X X N
2 T T T T T X X X X X N
Lines 3 T T T T X X X X X N
4 T T T X X X X
5 T X X X
Returns an array of lexemes. Newlines, eofs and spaces are the dividers.
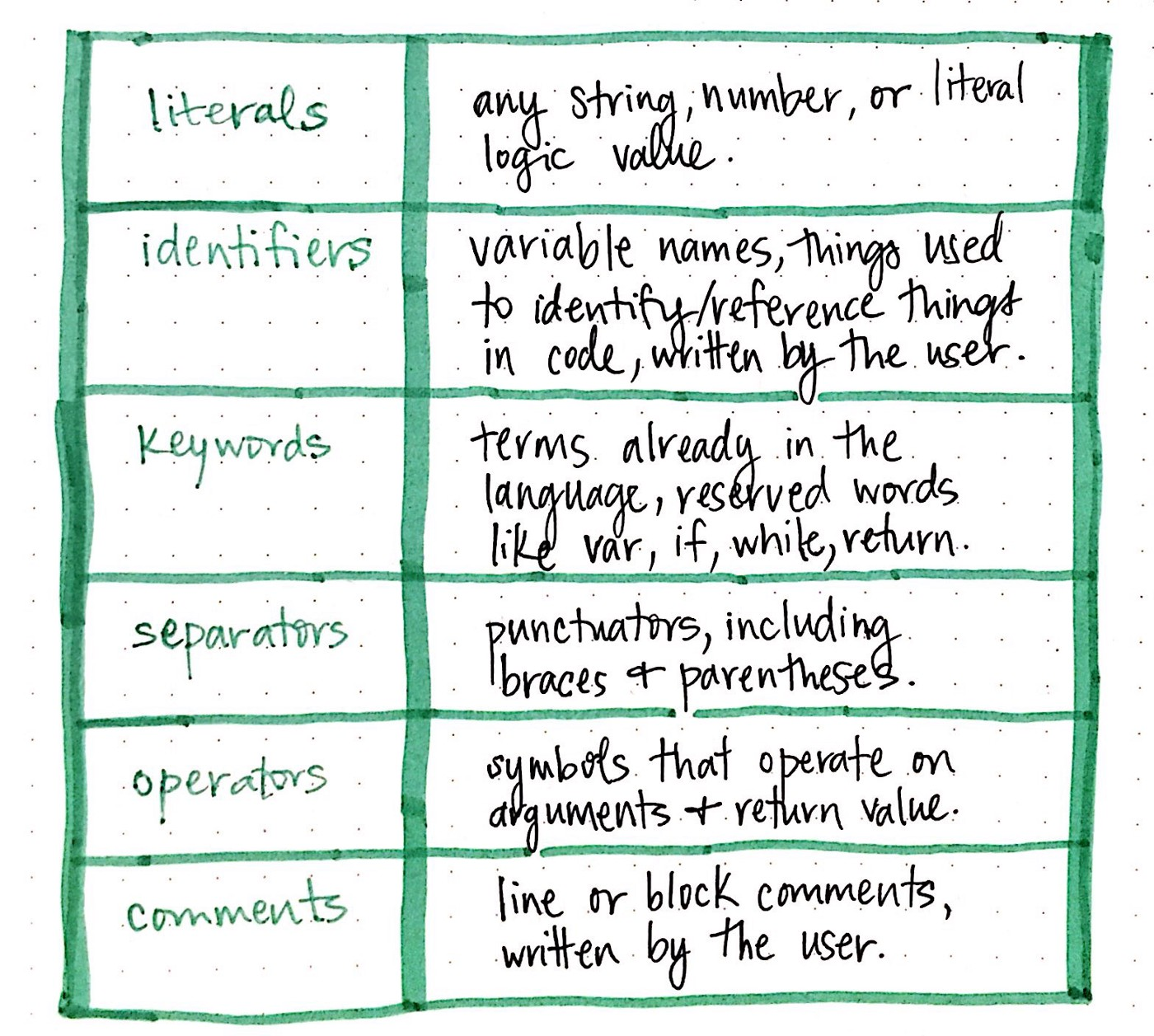
Determine what type of word it is. Then turn that word into a token. Tokens are lexemes/lexical units but with more information.
Lexer categories
An important thing to note about the tokenization process is that we’re neither tokenizing any whitespace (spaces, newlines, tabs, end of line, etc.), nor passing it on to the parser.
However, tabs and spaces and newlines are tokenized in a python compiler.
Scanner - is dumb. only breaks up a text blob into word blocks. it doesn't know what the words mean
Lexer - is smart. it knows the rules of language A. the lexer follows them to tokenize a word. It knows what the word means
Lexemes are said to be a sequence of characters (alphanumeric) in a token. There are some predefined rules for every lexeme to be identified as a valid token. These rules are defined by grammar rules, by means of a pattern. A pattern explains what can be a token, and these patterns are defined by means of regular expressions. In programming language, keywords, constants, identifiers, strings, numbers, operators and punctuations symbols can be considered as tokens.
the parse tree is built by looking at individual parts of the sentence and breaking down expressions into simpler parts.
Tokens ---> Syntax tree
A parse tree is a really just a “diagrammed” form of a sentence; that sentence could be written in any language, which means that it could adhere to any set of grammatical rules.

🎄
Bubble sort em
Flip them trees
Self balanced
Trie me
Scrollin'
Analyzing...
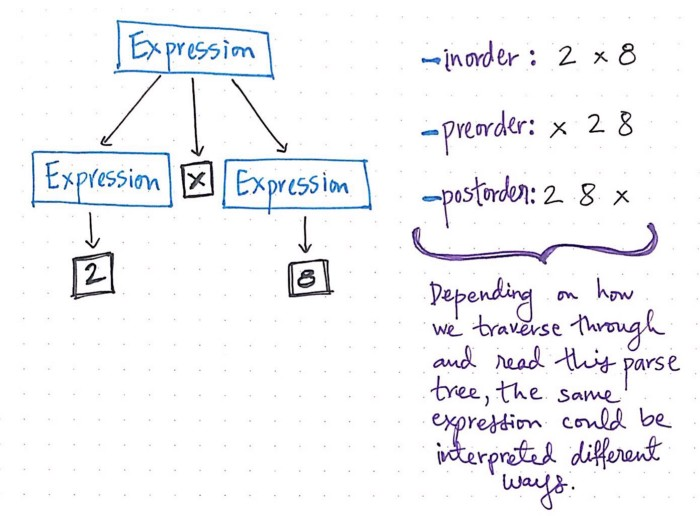
The parser can come up with a few different results in building the tree for the same grammar. The compiler will get confused because it doesn't know how to make sense out of the token set. Give the parser some rules.
Responsibilities:
- When given a valid sequence of tokens, it must be able to generate a corresponding parse tree, following the syntax of the language.
- When given an invalid sequence of tokens, it should be able to detect the syntax error and inform the programmer who wrote the code of the problem in their code.
7/19/2022 130ish am Parse tree - Complete representation. Has all characters whether they're important or not AST - Abstract Syntax Tree; abstract representation of the input. Some characters like the parentheses and brackets are not included.
Ast is easier to work with so i'll use that
Source: Medium.com - Vaidehi Joshi
Phase 0 Language A
Phase 1: Lexical Analysis
Phase 2: Syntax Analysis