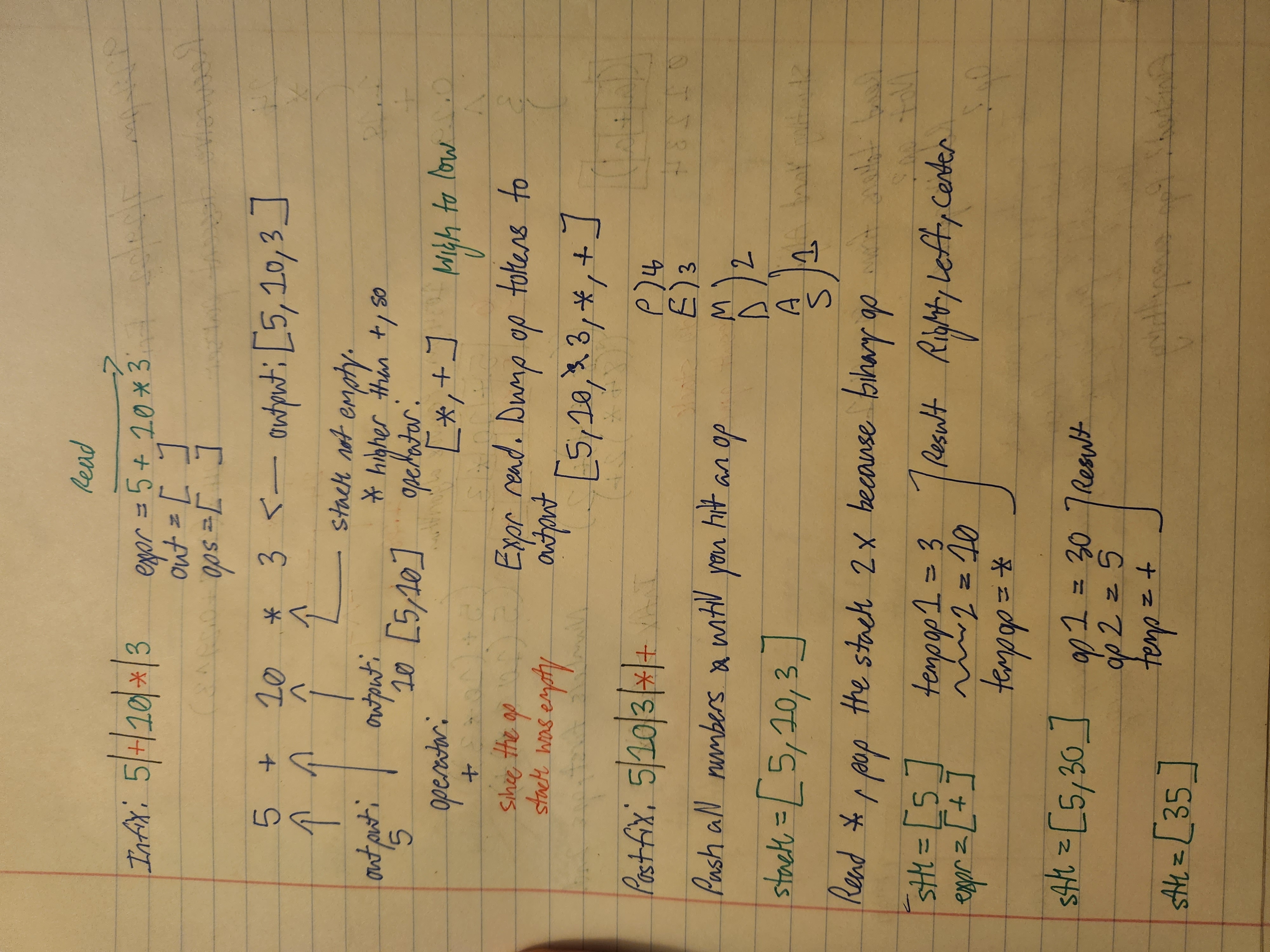Parser operation
Before I begin, a shoutout to Jaime Builds for his repository in javascript. Now I don't have to spend time translating from Python to JS! https://github.com/jamiebuilds/the-super-tiny-compiler/blob/master/the-super-tiny-compiler.js
I'll just copy and paste the parser and analyze it line by line.

Renaming placeholder.js to testing.js.
Code type A ----> compiler -------> Code type B
Apparently there are six steps:
Explanation of how a compiler works
-
Lexical Analysis
- Process:
- Source code : put line by line into the lexer
- Lexeme : a sequence of characters split from a string
- Token : object that describes the lexeme.
- Information:
- What type of lexeme is it?
- What value does the lexeme hold?
- Defines the vocabulary
- Array of token objects
- Process:
-
Syntax Analysis
- Process:
- Array of token objects
- tokens - Lego bricks
- Abstract syntax tree
: represents the logical structure of the program
- First looks for:
- Proper grammar
- Syntax correctness
- If everything checks out, build the tree. Otherwise, throw an error
- First looks for:
- Heavily nested ast object
- Array of token objects
- Process:
-
Semantic Analysis
- Process:
- Heavily nested ast object
- Traversal of the tree
: Navigate to each node of the tree
- checks for any semantic errors
- assigning the wrong type to a variable
- declaring variables with the same name in the same scope
- using an undeclared variable
- using language’s keyword as a variable name
- Steps
- Type checking – inspects type match in assignment statements, arithmetic operations, functions, and method calls.
- Flow control checking – investigates if flow control structures are used correctly and if classes and objects are correctly accessed.
- Label checking – validates the use of labels and identifiers.
- checks for any semantic errors
- Annotated AST
- Process:
-
Intermediate Code Generation
- High-Level – similar to the source language. In this form, we can easily boost the performance of source code. However, it’s less preferred for enhancing the performance of the target machine.
- Low-Level – close to the machine’s machine code. It’s preferred for making machine-related optimizations.
-
Optimization : the compiler uses a variety of ways to enhance the efficiency of the code.Optimization is skipped because I want to translate the code only -
Code Generation: Finally, the compiler converts the optimized intermediate code to the target language
Looking at jamiebuilds' parser now.
In:
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' }
]
Out:
{
type: 'Program',
body: [ { type: 'CallExpression', name: 'add', params: [Array] } ]
}
- Program [root]
- CallExpression (add)
- NumberLiteral {2} - params 1
- CallExpression (subtract)
- NumberLiteral {4} - params 2a
- NumberLiteral {2} - params 2b
- CallExpression (add)
Basically this tree right here:
Program
|
|
|
CallExpression (add)
/ \
/ \
NumberLiteral {2} CallExpression (subtract)
/ \
/ \
NumberLiteral {4} NumberLiteral {2}
Recap: How to access stuff in a object
findit.middleName
findit["middleName"]
The node is an object. Nodes carry smaller nodes in their arrays.
I was going to build my own function of traversing all of the nodes, but the solution was already done. I'll still build one though.
Plan for my parser
Reserved id tokens - add, subtract, print, function, whatever shouldn't be used as a regular name for your language
- make a node out of them that can carry other nodes [branch]
Regular id or number or operator or character tokens
- make a node out of them [leaf]
- or combine the tokens together into a leaf node if they match a proper sequence
Tokens with character values: ( , ) , [ , ] , { , }
- Architect tokens. Defines the structure of the ast. Don't make nodes out of them
Tokens with unwanted character values: IGNORE
-> Program (enter)
-> CallExpression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Call Expression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Number Literal (enter)
<- Number Literal (exit)
<- CallExpression (exit)
<- CallExpression (exit)
<- Program (exit)
function traverser(ast, visitor) {
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
function traverseNode(node, parent) {
let methods = visitor[node.type];
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'CallExpression':
traverseArray(node.params, node);
break;
case 'NumberLiteral':
case 'StringLiteral':
break;
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
}
//
traverseNode(ast, null);
}
(add 2 (subtract 4 2))
Rewriting the parser by switching the if statements to switch...cases Manual optimization of the code
if (token.type === 'string')
---> case 'string': ... break; switch(token.type)
if (token.type === 'paren' && token.value === '(')
---> case '(': ... break; switch(token.value)
while (token.type !== 'paren' || (token.type === 'paren' && token.value !== ')'))
---> while(token.value != ')')
!== to !=
=== to =
The token values are already of the same type.
default section in walk function:
If the token type/value is unknown, you need a way to stop the while loop or else the walk function will keep executing
current = token.length //okay but ruins the whole parsing process after the invalid token. token = tokens[++current]; //skip the invalid token. The invalid one is undefined.
Dot notation: access object properties
BACK TO PARSER
How do I form a syntax tree out of the syntax of this:
class Person{
public:
Person();
Person(string fullName, int howOld);
private:
string name;
int age;
};
Person buzz("Hughie", 28)
?
Or this:
function helpMe(there){
return there
}
?
Breaking down JaimeBuild's parser. So I can reverse engineer it. Can the walk function be used outside the parser function itself?

Because both functions share a variable named current. Both of JamieBuilds' and Siraj Raval's parsers use the variable to run the while loop that may act as a base case for the walk function. To prevent infinite recursion. And their walk functions use current to keep track of which token they are on.
Apparently the while loop isn't needed after all. I was expecting the parser to crash. Actually, the walk function executed once and only parsed the first token. I'll need to put a for loop inside the walk function itself to alleviate this.
var tokens = [
{ type: 'number', value: '8' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
];
{ type: 'Program', body: [ { type: 'NumberLiteral', value: '8' } ] }
Having an issue with my parser. Honestly thought omitting the while loop in the parser and putting the loop in the walk function thats above the parser would work.
function parser(tokens) {
let ast = {
type: 'Base',
body: []
};
//executes once. Not the outcome I was going for
ast.body.push(walk(/*some content here*/));
return ast;
}
Make current variable global.
The parser works now.
Learning about trees since yesterday afternoon. Still a bit stumped on them. Made a YouTube playlist on trees to help me out with learning postorder, preorder, and inorder traversal. Figured it would clarify how I should establish the order of importance like in PEMDAS.
The parser turns tokens into nodes in order. 0 to n-1
Discovered ASTExplorer AST Maker
let tips = [
"Click on any AST node with a '+' to expand it",
"Hovering over a node highlights the \
corresponding location in the source code",
"Shift click on an AST node to expand the whole subtree"
];
function printTips() {
tips.forEach((tip, i) => console.log(`Tip ${i}:` + tip));
}
Checked the Ast for this. That is a lot of shit for this source code here
Time to get started.
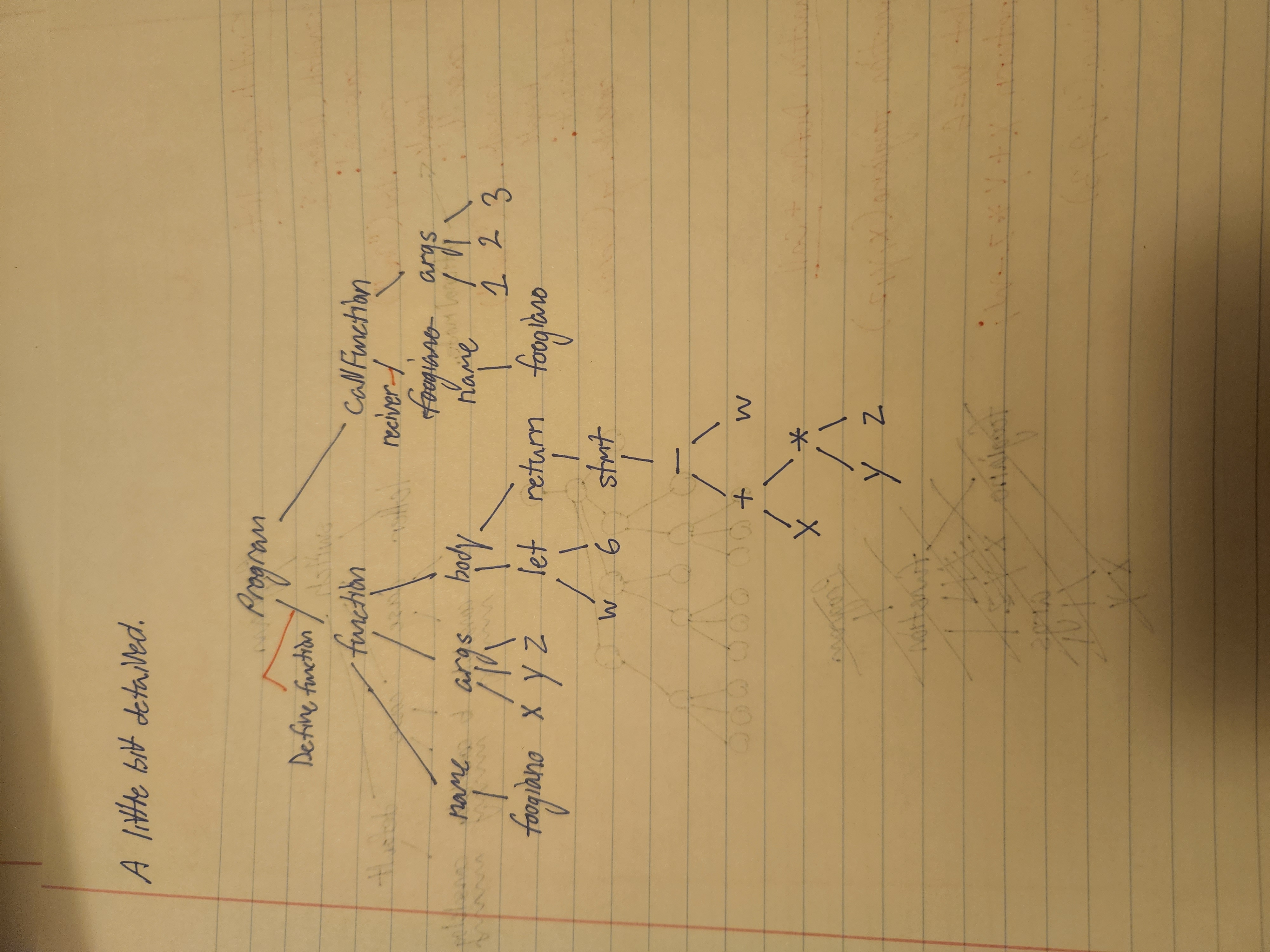
Node types:
for example, parse this:
function foogiano(x, y, z)\
{\
let w = 6\
return x + y * z - w;\
}
//Functions
{
type: 'DeclareFunction',
name: token.value, //foogiano
args: [] //Id objects w values x, y, and z
stmts: [
//all statements inside this block live here
]
}
//commas ignored.
//Declaring variables let w = 6
//variable #1
{
type: 'DeclareThisVariable'
kind: 'let'
id: {
type: 'Identifier',
value: token.value //w
}
init: {
type: 'NumberLiteral',
value: token.value //6
}
/*
or: ["A","B"]
{
type: 'ArrayExpr',
elements: [
{
type: 'StringLiteral',
value: token.value //"A"
},
{
type: 'StringLiteral',
value: token.value //"B"
},
]
}
//Brackets ignored.
*/
}
}
//variable #2
{
}
//equal sign, commas, and semicolons ignored.
//for loop
for(let i = 0; i < 5; i++){\
}
{
type:'ForLoopStatement'
init: <VariableDeclare>
cond: <BinaryExpr> left i, right 5, op <
update: {
operator: ++
prefix: false
arg: {
Id, i
}
}
stmts: [
//body here
]
}
//while loop
let i=0
while( i < 5){\
i++
}
{
<VariableDeclare>
}
{
type:'WhileLoopStatement'
cond: <BinaryExpr> left i, right 5, op <
stmts: [
//body here
update: {
operator: ++
prefix: false
arg: {
Id, i
}
}
]
}
//conditional statements
if(answer >= 90){
console.log("Yes")
} else if(answer >= 80){
console.log("Ok")
} else {
console.log("Ehh")
}
{
type: 'IfStatement'
cond: {
left: {
type: 'Identifier'
value: 'answer'
}
operator: '>='
right: {
type: 'NumberLiteral'
value: '90'
}
}
then: [
//if 90 or higher, Yes
]
else: [
//if lower than 90
{
type: 'IfStatement'
cond: {
left: {
type: 'Identifier'
value: 'answer'
}
operator: '>='
right: {
type: 'NumberLiteral'
value: '80'
}
}
then: [
//if 80 or higher, ok
]
else: [
//if lower than 80
//other stuff here
]
}
]
}
//return stmt
{
type: 'ReturnStatement'
returnstmt: {
//some stuff later
}
}
//colon ignored*
//call function foogiano(9,8,7)
{
type: 'CallFunction',
name: token.value, //foogiano
args: [] //NumberLiteral objects w values 9, 8, and 7
}
//commas and semicolons ignored.
//Access array element alex[4]
{
type: 'MemberExpression'
name: 'alex'
find: {
type: 'NumberLiteral',
value: token.value
}
}
//Assign new value to existing variable
result = "Yes"
{
type: 'AssignItSomething'
left: {
type: 'identifier'
value: 'result'
}
op: '=' //or +=
right: {
type: 'StringLiteral'
value: 'Yes'
}
}
//Parse this object:
var character = {
name: 'Mando',
age: 38,
friends:{
name1: 'Baby Yoda',
name2: 'Cara Dune',
name3: 'Greef Karga',
},
weapons:["Knives","Birds","Guns","Bombs","Darksaber"]
}
{
type: 'DeclareThisVariable'
kind: 'let'
id: {
type: 'Identifier',
value: token.value
}
init: {
type: 'DefineObject'
properties: [
{
type: 'ThisProperty'
key: 'name'
value: 'Mando'
}
...
{
type: 'ThisProperty'
key: 'friends'
value: {
type: 'DefineObject'
properties: [
{
type: 'ThisProperty'
key: 'name1'
value: 'Baby Yoda'
}
...
]
}
}
{
type: 'ThisProperty'
key: 'weapons'
value: {
type: ArrayExpr
elements: [
{
type: 'StringLiteral',
value: token.value //Knives
}
]
}
}
]
}
}
}
1111pm - Syntax analysis is a more intimidating topic than lexical analysis. I'm currently simplifying the ast nodes so I can understand the generic logical structure.
ASTExplorer like regex101 is very helpful. But it's a little too detailed.
414pm - Got confused on how to define Callexpression and Memberexpression node types in the ast diagram
StackOverflow:
func() is a CallExpression
thing.func is a MemberExpression
thing is the object of the MemberExpression
func is the property of the MemberExpression
thing.func() is a MemberExpression within a CallExpression - So expression statement. 432pm
thing.func is the callee of the CallExpression
So:
console.log("Yes") <-- Expr stmt; deffo dot operator in ast diagram
console <-- object
log <--- property
console.log(...) <---function call. Actually not a dot op. Punctuations get ignored in ast.
Parent is CallExpression node. Or simply Call node.
Also, found a website that explains grammar rules for javascript parsing.
All Grammar Rules
Intermediate code generation - deep copying asts
let obj2 = JSON.parse(JSON.stringify(obj1))
//Switch statement parsing
switch(letter){
case 'a':
break;
case 'b':
break;
default:\
}
{
type: 'SwitchStatement'
test: {
variable named letter
}
cases: [
{
type: 'ThisCaseStatement'
match: {
id named 'a'
}
then: [
//some code here
{
//break is optional
type: 'BreakStatement'
}
]
}
{
type: 'ThisCaseStatement'
match: {
id named 'b'
}
then: [
//some code here
{
type: 'BreakStatement'
}
]
}
{
type: 'DefaultCaseStatement'
else: [
//some code here
{
type: 'BreakStatement'
}
]
}
]
}
Set PEMDAS rules for parser. ASTExplorer got the return statement hierarchy wrong.
Statement: x + y * z - w
Should be:
*
/ \
+ -
/ \ / \
x y z w
ASTExplorer got:
-
/ \
+ w
/ \
x *
/ \
y z
ASTExplorer actually got it right. higher level nodes are the later steps, lower level nodes are the earlier steps.
Before I went on to rebuilding the walk function, I wanted to draw out syntax tree diagrams based on what ASTExplorer generated; just to help me define
my node objects. And to visualize how the walk function actually arranges the tokens into a tree.
Again, the terminology for the ast info was verbose, so I gave different property names for the nodes because I wanted to make the ast info clearer.\
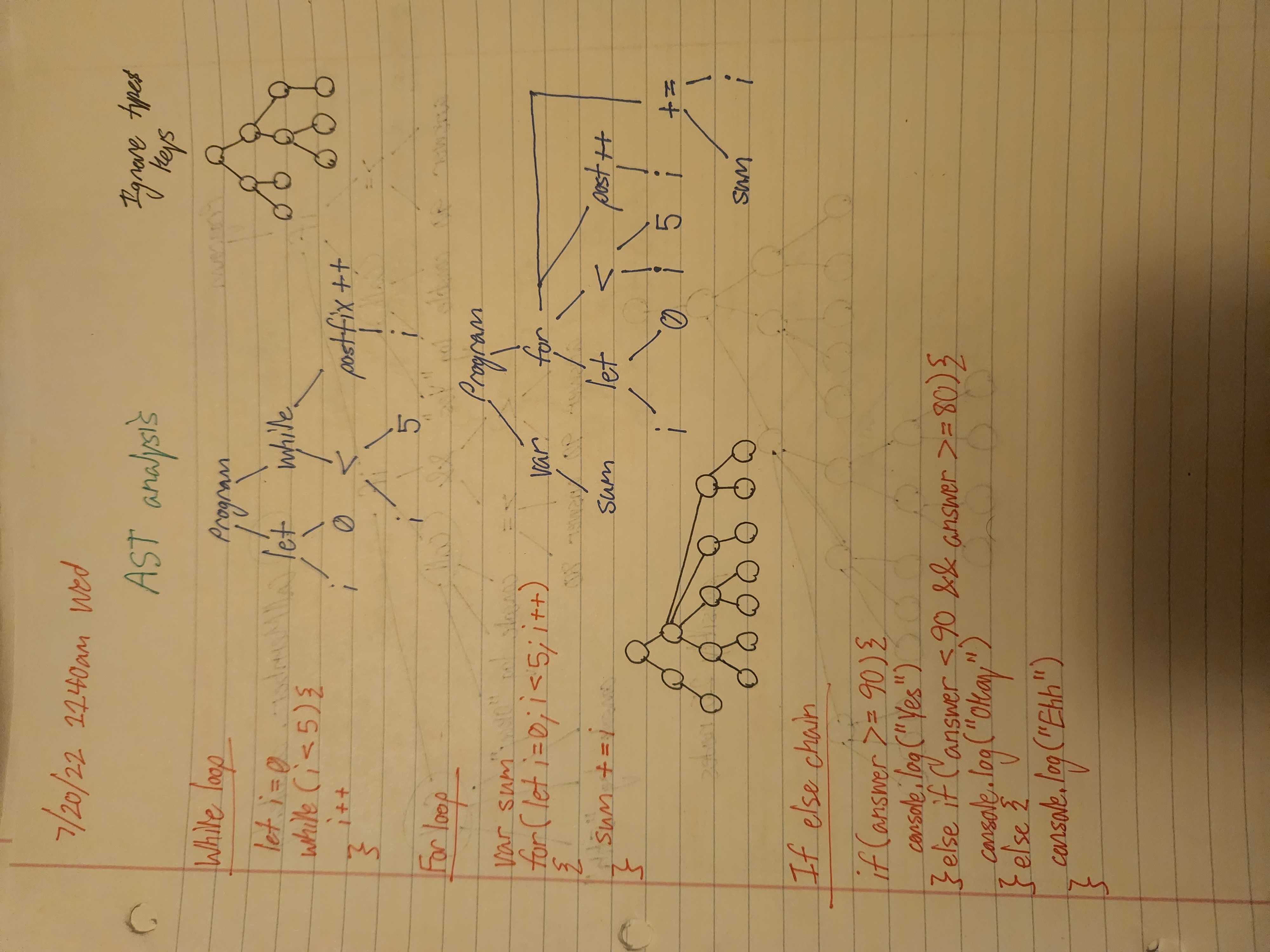
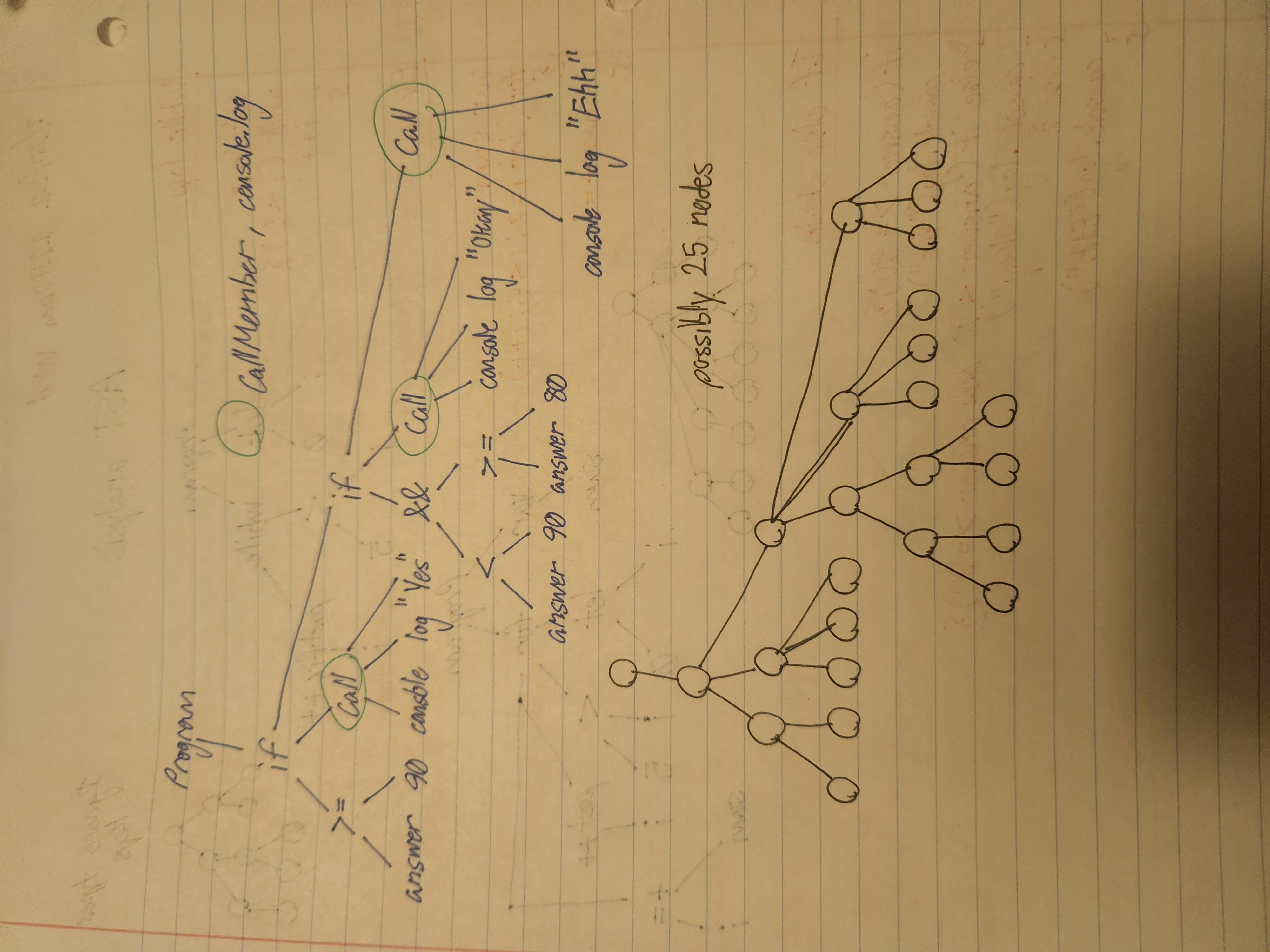
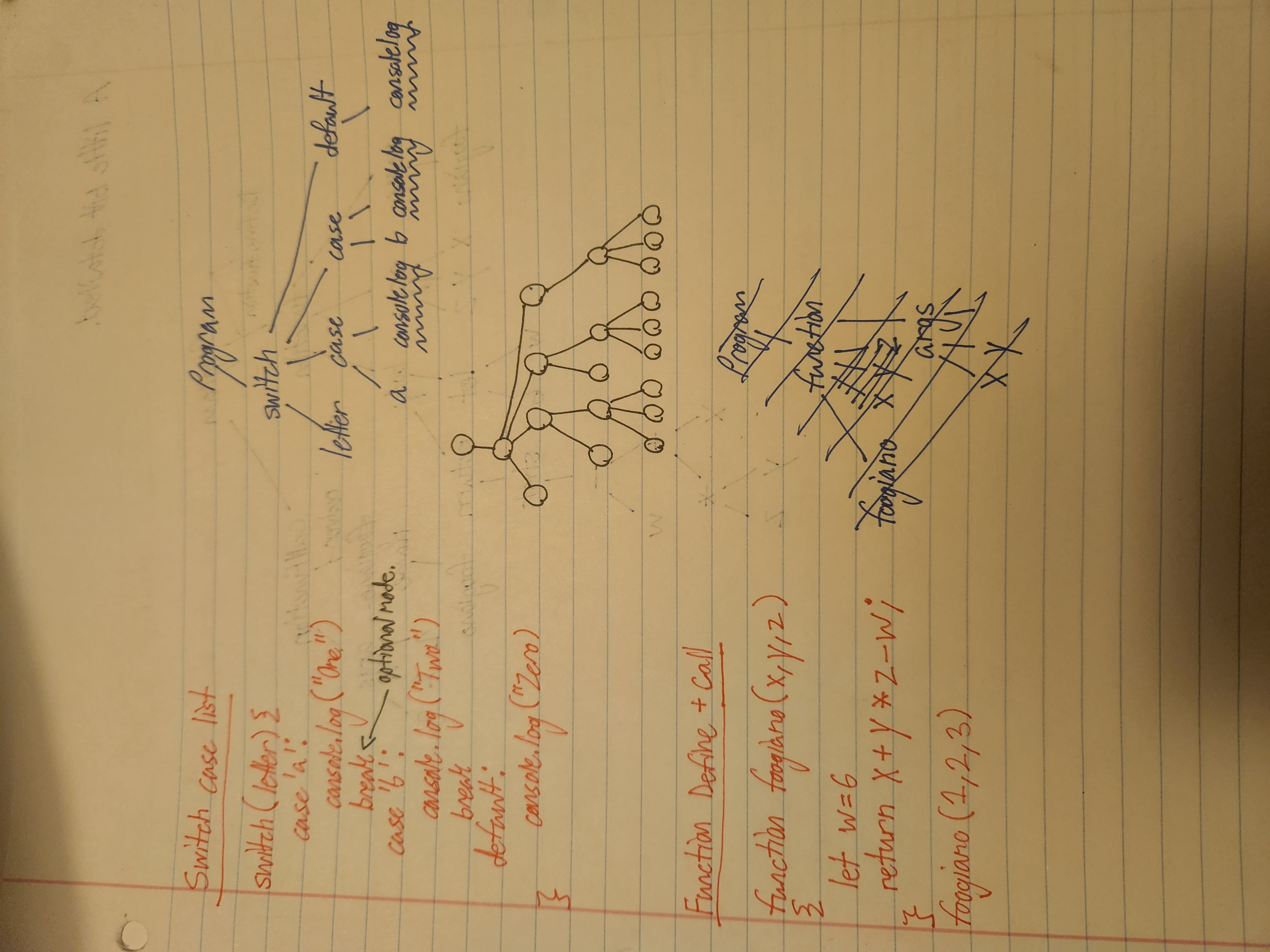
Building the walk function to handle
answer = 4 + 6 + 7^2 - ( 4*8 / 2 )
Total of tokens is 17.
I can't just have my parser build a node from left to right in the tokens array.
Should parse:
Program
|
|
=
/ \
answer +
/ \
4 +
/ \
6 -
/ \
^ *
/ \ / \
7 2 4 /
/ \
8 2
Learning how to erase all array contents.
Flush Array
arr.splice(0, arr.length)
Constructing walk function now. Question: Do I use a stack to push arithmetic stuff in order temporarily? And then pop them as nodes?
Focus on one statement at a time. Starting with switch statements. For now, the parser can handle switch statements. Specifically keywords switch, case, and default. The Identifier type node has already been made
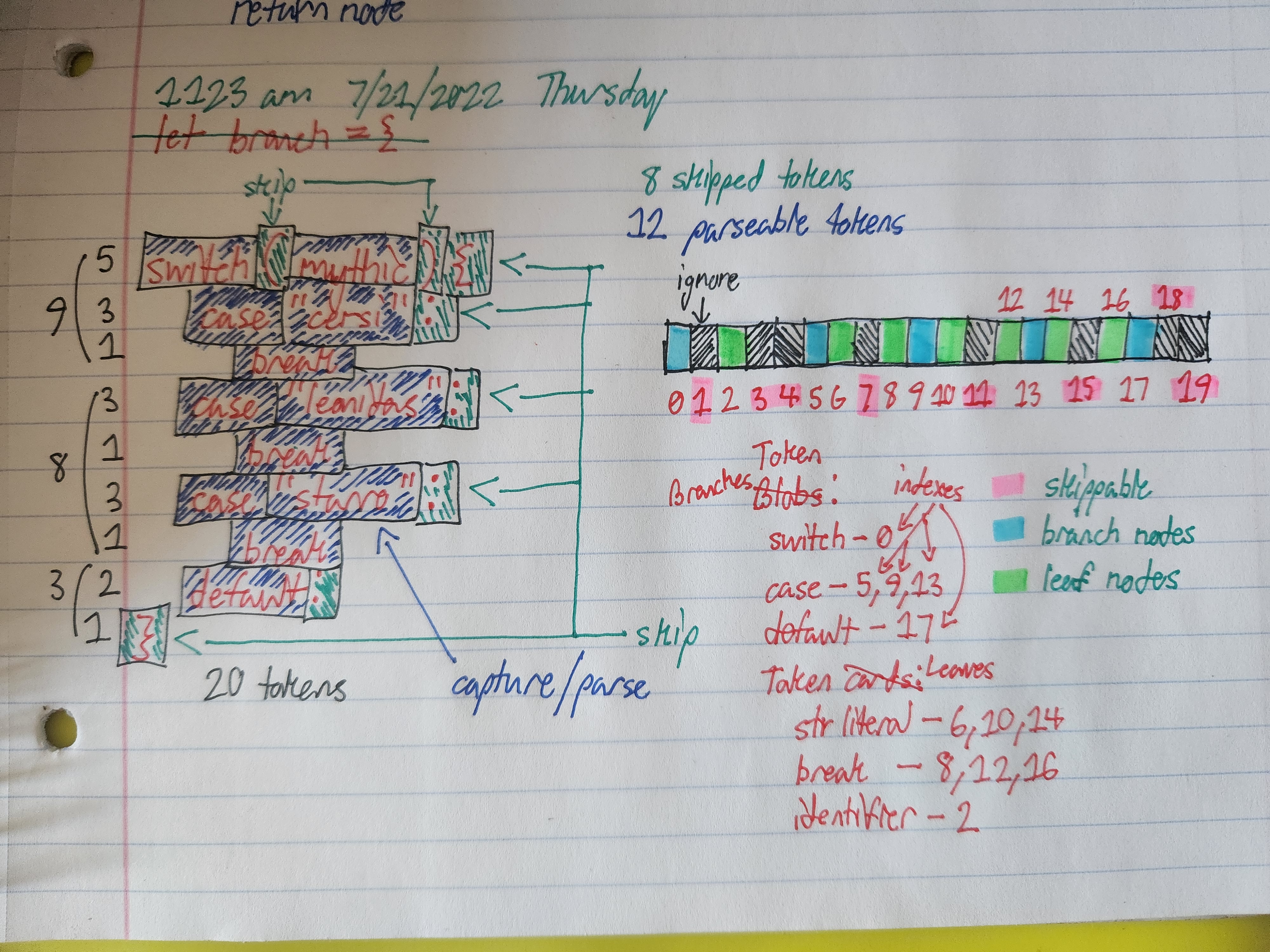
Ran into tokenizing bug. Tried to write
switch(mythic){
case "cersi":
break
case "leonidas":
break
case "starro":
break
default:
}
but got 18 tokens:
{ type: 'reserved' , value: 'switch' },
{ type: 'punctuator' , value: '(' },
{ type: 'identifier' , value: 'mythic' },
{ type: 'reserved' , value: 'case' },
{ type: 'string' , value: '"cersi"' },
{ type: 'punctuator' , value: ':' },
{ type: 'reserved' , value: 'break' },
{ type: 'reserved' , value: 'case' },
{ type: 'string' , value: '"leonidas"' },
{ type: 'punctuator' , value: ':' },
{ type: 'reserved' , value: 'break' },
{ type: 'reserved' , value: 'case' },
{ type: 'string' , value: '"starro"' },
{ type: 'punctuator' , value: ':' },
{ type: 'reserved' , value: 'break' },
{ type: 'reserved' , value: 'default' },
{ type: 'punctuator' , value: ':' },
{ type: 'punctuator' , value: '}' },
Should be 20 tokens. Both punctuators ) and { are missing because of this punctuator lexing algorithm in the scanner:
if (char.match(PUNCTUATION)) {
//Actually this whole loop itself is causing the issue. It's also not needed at all.
while (char.match(PUNCTUATION)) {
if (index + 1 == everything.length) {
break;
}
lexeme += char; //this line is causing the issue.
char = everything[++index];
}
divvy.push(lexeme);
char = everything[--index] //remove this too
}
How did I miss that?
Fixing:
if (char.match(PUNCTUATION)) {
lexeme = char;
divvy.push(lexeme);
}
The punctuator characters are a lexeme. Don't add them together
Priorities:
- Switch statements keywords: switch, case, default, break, return*
- If else statements keywords: if, else
- Loops keywords: const, let, var, for, while, of, in
Drawing typical switch syntax to visualize what the parser will focus on. Obviously, the parser will ignore some punctuators like: ( , ), {, }, and :

Ran into trouble with the while loop inside case switch of switch statement testing for the matching reserved token name. Used an if statement instead.
Having the walk function build an ast for switch statements is harder than anticipated. Also, the terminal can't display nested objects and arrays
Simplified the switch statement complexity by splitting them in two.
switchStmt1 - discriminant is token.type
switchStmt2 - discriminant is token.value
The parser is not parsing the switch case properly.
[
{ type: 'SwitchStatement', test: [Object], cases: [] },
/* ast.body
{
type: 'SwitchStatement',
test: { type: 'Identifier', value: 'mythic' },
cases: []
},
*/
{ type: 'ThisCaseStatement', match: {}, then: [] },
{ type: 'StringLiteral', value: '"cersi"' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'ThisCaseStatement', match: {}, then: [] },
{ type: 'StringLiteral', value: '"leonidas"' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'ThisCaseStatement', match: {}, then: [] },
{ type: 'StringLiteral', value: '"starro"' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'DefaultCaseStatement', else: [] },
{ type: 'BreakStatement', action: 'jump' },
{ type: 'BreakStatement', action: 'jump' }
]
Should be:
{
type: 'Program',
body: [
{ type: 'SwitchStatement',
test: { type: 'Identifier', value: 'mythic' },
//Expected
cases: [
{ type: 'ThisCaseStatement',
match: { type: 'StringLiteral', value: '"cersi"' },
then: [
{ type: 'BreakStatement', action: 'jump' },
]
},
{ type: 'ThisCaseStatement',
match: { type: 'StringLiteral', value: '"leonidas"' },
then: [
{ type: 'BreakStatement', action: 'jump' },
]
},
{ type: 'ThisCaseStatement',
match: { type: 'StringLiteral', value: '"starro"' },
then: [
{ type: 'BreakStatement', action: 'jump' },
]
},
{ type: 'DefaultCaseStatement',
else: []
},
]
},
AST explorer
Location data - index of all characters. Starting index to ending index
Also: object to string, JSON.stringify(thisobject)
I CAN NOW SEE MY AST'S !!!!!!
JSON stringified
{"type":"Program","body":[{"type":"CallExpression","name":"subtract","args":[{"type":"NumLiteral","value":"2"},{"type":"NumLiteral","value":"2"}]}]}
Better readability:
{ "type":"Program",
"body":[
{ "type":"CallExpression",
"name":"subtract",
"args":[
{ "type":"NumLiteral",
"value":"2"},
{ "type":"NumLiteral",
"value":"2"}
]
}
]
}
My terminal can now display nested objects and arrays. But its a lot to unnest. Luckily, the strings can be arranged for better readability
Going to build an algorithm that will indent and tab the now string typed ast when it sees a comma, or left { or left [
The single line comment ignorer was malfunctioning since I had my scanner push "" lexemes instead of "\n" lexemes which the ignorer was looking for to stop looping
Discovery
var drax = -9.0e0
-|+ 9.0
//VariableDeclarator node
init: {
type: "UnaryExpression",
operator: "-" | "+",
argument: {
type: "Literal",
value: 90, //method to calculate input accurately
raw: "9.0e1" //from input
}
}
Decimal points and scientific notation are accepted as number literals. As for positive and negative sign exponents:
var drax = 9e +|- 2
//VariableDeclarator node
"init": {
"type": "Literal",
"value": 9800,
"raw": "9.8e+3"
}
I didn't understand this block of the walk function. After breaking it down, I do now. The function of this loop was already obvious.
while (token.value != ')') {
node.params.push(walk()); //call this function again. Each node will be collected here one at a time.
//since current is already updated by 1 when generating other nodes, this line will get the current token, which will be tested by the loop's condition.
token = tokens[current];
}
Pemdas algorithm. Thought it would help