Three-dimensional objects are commonly represented as 3D boxes in a point-cloud. This representation mimics the well-studied image-based 2D bounding-box detection but comes with additional challenges. Objects in a 3D world do not follow any particular orientation, and box-based detectors have difficulties enumerating all orientations or fitting an axis-aligned bounding box to rotated objects. In this paper, we instead propose to represent, detect, and track 3D objects as points. Our framework, CenterPoint, first detects centers of objects using a keypoint detector and regresses to other attributes, including 3D size, 3D orientation, and velocity. In a second stage, it refines these estimates using additional point features on the object. In CenterPoint, 3D object tracking simplifies to greedy closest-point matching. The resulting detection and tracking algorithm is simple, efficient, and effective. CenterPoint achieved state-of-the-art performance on the nuScenes benchmark for both 3D detection and tracking, with 65.5 NDS and 63.8 AMOTA for a single model. On the Waymo Open Dataset, CenterPoint outperforms all previous single model method by a large margin and ranks first among all Lidar-only submissions.
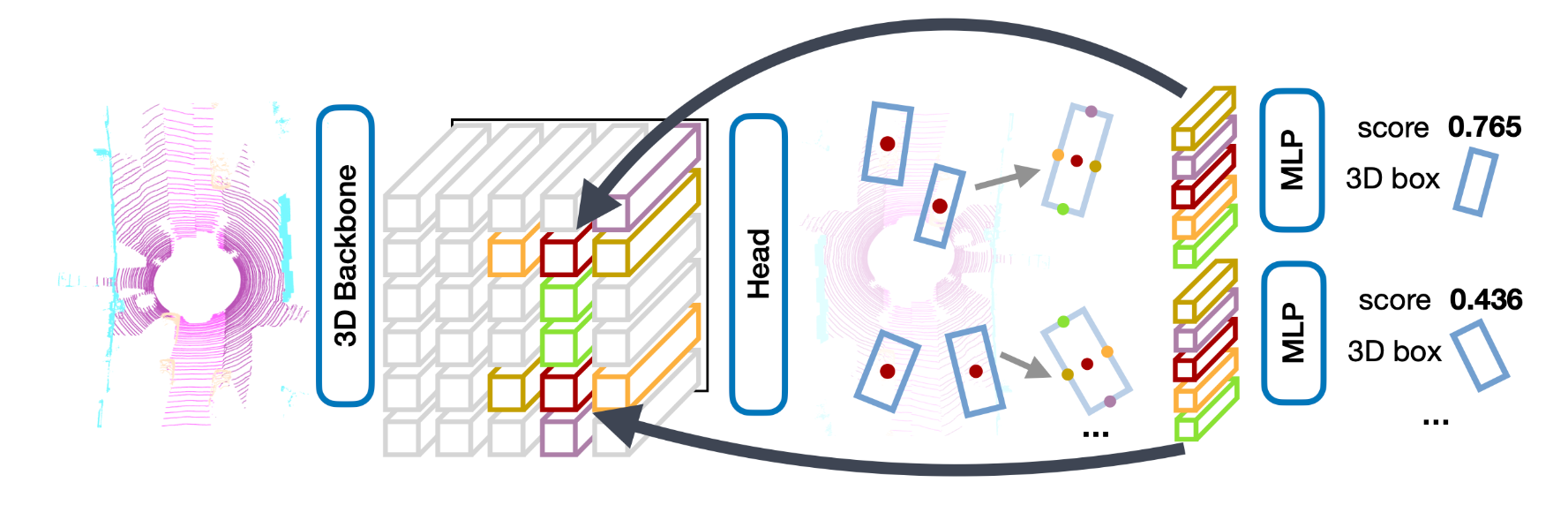
We implement CenterPoint and provide the result and checkpoints on nuScenes dataset.
We follow the below style to name config files. Contributors are advised to follow the same style.
{xxx} is required field and [yyy] is optional.
{model}: model type like centerpoint.
{model setting}: voxel size and voxel type like 01voxel, 02pillar.
{backbone}: backbone type like second.
{neck}: neck type like secfpn.
[dcn]: Whether to use deformable convolution.
[circle]: Whether to use circular nms.
[batch_per_gpu x gpu]: GPUs and samples per GPU, 4x8 is used by default.
{schedule}: training schedule, options are 1x, 2x, 20e, etc. 1x and 2x means 12 epochs and 24 epochs respectively. 20e is adopted in cascade models, which denotes 20 epochs. For 1x/2x, initial learning rate decays by a factor of 10 at the 8/16th and 11/22th epochs. For 20e, initial learning rate decays by a factor of 10 at the 16th and 19th epochs.
{dataset}: dataset like nus-3d, kitti-3d, lyft-3d, scannet-3d, sunrgbd-3d. We also indicate the number of classes we are using if there exist multiple settings, e.g., kitti-3d-3class and kitti-3d-car means training on KITTI dataset with 3 classes and single class, respectively.
We have supported double-flip and scale augmentation during test time. To use test time augmentation, users need to modify the
test_pipeline and test_cfg in the config.
For example, we change centerpoint_0075voxel_second_secfpn_circlenms_4x8_cyclic_20e_nus.py to the following.
_base_ = './centerpoint_0075voxel_second_secfpn_circlenms' \
'_4x8_cyclic_20e_nus.py'
model = dict(
test_cfg=dict(
pts=dict(
use_rotate_nms=True,
max_num=83)))
point_cloud_range = [-54, -54, -5.0, 54, 54, 3.0]
backend_args = None
class_names = [
'car', 'truck', 'construction_vehicle', 'bus', 'trailer', 'barrier',
'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'
]
test_pipeline = [
dict(
type='LoadPointsFromFile',
load_dim=5,
use_dim=5,
backend_args=backend_args),
dict(
type='LoadPointsFromMultiSweeps',
sweeps_num=9,
use_dim=[0, 1, 2, 3, 4],
backend_args=backend_args,
pad_empty_sweeps=True,
remove_close=True),
dict(
type='MultiScaleFlipAug3D',
img_scale=(1333, 800),
pts_scale_ratio=[0.95, 1.0, 1.05],
flip=True,
pcd_horizontal_flip=True,
pcd_vertical_flip=True,
transforms=[
dict(
type='GlobalRotScaleTrans',
rot_range=[0, 0],
scale_ratio_range=[1., 1.],
translation_std=[0, 0, 0]),
dict(type='RandomFlip3D', sync_2d=False),
dict(
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
]),
dict(type='Pack3DDetInputs', keys=['points'])
]
data = dict(
val=dict(pipeline=test_pipeline), test=dict(pipeline=test_pipeline))| Backbone | Voxel type (voxel size) | Dcn | Circular nms | Mem (GB) | Inf time (fps) | mAP | NDS | Download |
|---|---|---|---|---|---|---|---|---|
| SECFPN | voxel (0.1) | ✗ | ✓ | 5.2 | 56.11 | 64.61 | model | log | |
| above w/o circle nms | voxel (0.1) | ✗ | ✗ | x | x | |||
| SECFPN | voxel (0.1) | ✓ | ✓ | 5.5 | 56.10 | 64.69 | model | log | |
| above w/o circle nms | voxel (0.1) | ✓ | ✗ | x | x | |||
| SECFPN | voxel (0.075) | ✗ | ✓ | 8.2 | 56.54 | 65.17 | model | log | |
| above w/o circle nms | voxel (0.075) | ✗ | ✗ | 57.63 | 65.39 | |||
| SECFPN | voxel (0.075) | ✓ | ✓ | 8.7 | 56.92 | 65.27 | model | log | |
| above w/o circle nms | voxel (0.075) | ✓ | ✗ | 57.43 | 65.63 | |||
| above w/ double flip | voxel (0.075) | ✓ | ✗ | 59.73 | 67.39 | |||
| above w/ scale tta | voxel (0.075) | ✓ | ✗ | 60.43 | 67.65 | |||
| above w/ circle nms w/o scale tta | voxel (0.075) | ✓ | ✗ | 59.52 | 67.24 | |||
| SECFPN | pillar (0.2) | ✗ | ✓ | 4.6 | 48.70 | 59.62 | model | log | |
| above w/o circle nms | pillar (0.2) | ✗ | ✗ | 49.12 | 59.66 | |||
| SECFPN | pillar (0.2) | ✓ | ✗ | 4.9 | 48.38 | 59.79 | model | log | |
| above w/ circle nms | pillar (0.2) | ✓ | ✓ | 48.79 | 59.65 |
Note: The model performance after coordinate refactor is slightly different (+/- 0.5 - 1 mAP/NDS) from the performance before coordinate refactor in v0.x branch. We are exploring the reason behind. |
@article{yin2021center,
title={Center-based 3D Object Detection and Tracking},
author={Yin, Tianwei and Zhou, Xingyi and Kr{\"a}henb{\"u}hl, Philipp},
journal={CVPR},
year={2021},
}