RIP 34 Support quorum write and adaptive degradation in master slave architecture
- Current State: Accpet
- Authors: RongtongJin
- Shepherds: duhengforever@apache.org
- Mailing List discussion: dev@rocketmq.apache.org
- Pull Request:
- Released: <relased_version>
- Related Docs: English 中文版
-
Will we add a new module?
No
-
Will we add new APIs?
No -
Will we add a new feature?
Quorum write and adaptive degradation will be supported in master-slave architecture
- Are there any problems of our current project?
In RocketMQ, there are two replication modes: synchronous replication and asynchronous replication:
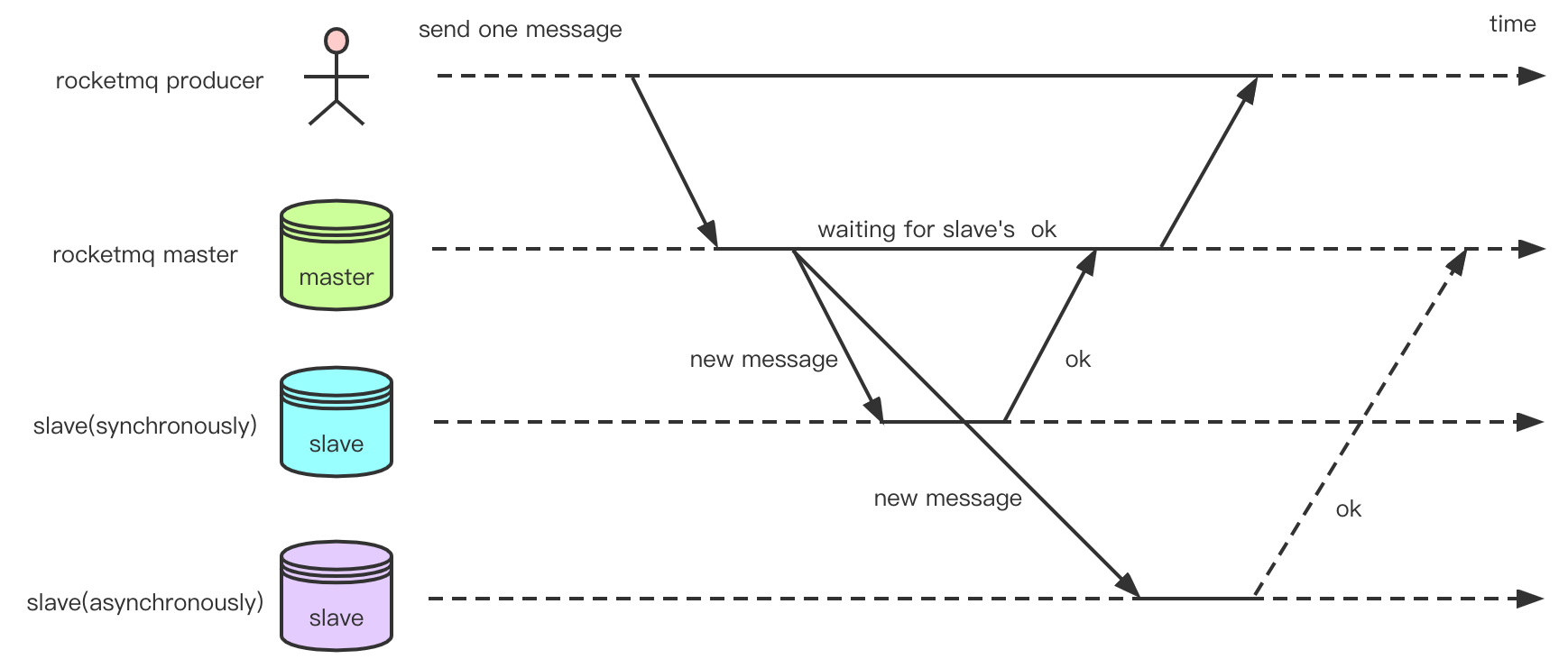
As shown in the figure above, Slave1's replication is synchronous. Before reporting an ack to the producer, the master needs to wait for slave1 to successfully copy the message. And Slave2's replication is asynchronous. The Master does not need to wait for Slave2 to respond. In RocketMQ, a message is sent, and if all goes well, the state is eventually returned to the client as PUT_OK, or FLUSH_SLAVE_TIMEOUT if the slave synchronization time out. If the Slave is unavailable or the CommitLog difference between the Slave and Master exceeds a certain value (default: 256MB), SLAVE_NOT_AVAILABLE is returned.
Synchronous replication ensures that data can still be found on the slave even after the master fails, which is suitable for scenarios with high-reliability requirements. Although messages may be lost in asynchronous replication, the efficiency of asynchronous replication is higher than that of synchronous replication because there is no need to wait for confirmation from the Slave. Therefore, asynchronous replication is suitable for scenarios that require certain efficiency.
However, only the two modes are not flexible enough. For example, asynchronous replication cannot meet the requirements in a scenario with three or even five copies and high-reliability requirements. However, synchronous replication returns only after each copy is confirmed. On the other hand, in synchronous replication mode, if a slave in the group feigned death, the whole transmission would fail until manual processing.
Therefore, RIP-34 will support quorum write. In synchronous replication mode, users can specify at the broker the minimum number of copies to be written before returning, and provide an adaptive degrade mode, which can be automatically degraded according to the number of surviving copies and commitLog gap between master and slave.
- What can we benefit from proposed changes?
-
Through parameter settings, in the master-slave synchronous replication mode, users can specify the minimum number of copies to be written before returning
-
Replication can automatically degrade based on the number of surviving copies and commitLog gap between master and slaveommitLog gap in the master-slave mode.
- What problem is this proposal designed to solve?
Solve the problem that the number of ACK cannot be specified freely and adaptive degradation cannot be completed in master-slave mode.
- What problem is this proposal NOT designed to solve?
The goal of this RIP is not to change the master-slave architecture, but to provide flexible ACK and adaptive degradation capabilities for synchronous replication.
In RIP-34, two parameters are added to support quorum write.
totalReplicas: specify the total number of brokers in the replica group. The default value is 1.
inSyncReplicas: specify the number of duplicate groups to be synchronized in normal cases. The default value is 1.
Using these two parameters, you can flexibly specify the number of copies to be ACK in synchronous replication mode.
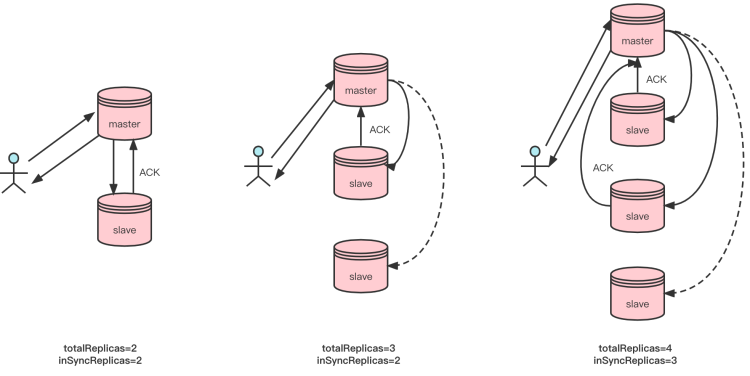
As shown in the figure above, in the case of two copies, if inSyncReplicas is 2, the message will be returned to the client only after being copied in both mmaster and slave. In the three-copy case, if inSyncReplicas is 2, the message must be copied to the master and to one slave before it is returned to the client. In the four-copy case, if inSyncReplicas is 3, the message needs to be copied to any two slaves in addition to the master before it is returned to the client. The totalReplicas and inSyncReplicas can be flexibly set to meet the needs of users in various scenarios.
Note:
totalReplicas parameter does not affect the number of replicas that need ack. Its main functions are as follows:
- In RIP-32, lock quorum (refer to RIP-32) calculates the number of replicas to be locked according to the value of totalReplicas. For example, if totalReplicas = 3, it needs to lock 2 replicas to be successful.
- It will be a verification parameter. For example, when totalReplicas = 1, it will only get the local data when calling getMinOffset and getMaxOffset. It will also skip the pre-online process when totalReplicas = 1.
Therefore, if the real number of replicas is not equal to the configured totalReplicas, the normal replication will not be affected, but lock quorum will not be as expected in the scenario of order message.
RIP-34 can perform adaptive synchronous replication degradation. The degradation criteria are as follows
-
Number of surviving copies of the current replica group
-
The gap between master commitlog and slave commitlog
RIP-34 Adds the following parameters to perform automatic degradation:
minInSyncReplicas: specify the minimum number of duplicate groups to be synchronized. This parameter takes effect only when enableAutoInSyncReplicas is true. The default value is 1.
enableAutoInSyncReplicas: automatic degrade switch. When enableAutoInSyncReplicas is enabled, if the number of synchronized brokers (including the master itself) in the replication group does not meet the threshold specified by inSyncReplicas, minInSyncReplicas is used. The conditions for determining the synchronization status are as follows: slave commitlog The length of the master cannot exceed haSlaveFallBehindMax. The default is false.
haMaxGapNotInSync: specify the judgment value of whether the slave and master are in the in-sync state. If the slave commitLog lag behind the master exceeds this value, the slave is considered to be in the unsynchronized state.. The default value is 256 KB.
Note: In RocketMQ 4.x, haSlaveFallbehindMax exists. The default value is 256MB. In RIP-34, this parameter is removed.
In RIP-34, the following logic is used to calculate the number of ACK copies required. After receiving sufficient ACK copies, return the success to the client.
//Compute needAckNums
int inSyncReplicas = Math.min(this.defaultMessageStore.getAliveReplicaNumInGroup(),
this.defaultMessageStore.getHaService().inSyncSlaveNums(currOffset) + 1);
needAckNums = calcNeedAckNums(inSyncReplicas);
if (needAckNums > inSyncReplicas) {
// Tell the producer, don't have enough slaves to handle the send request
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.IN_SYNC_REPLICAS_NOT_ENOUGH, null));
}
private int calcNeedAckNums(int inSyncReplicas) {
int needAckNums = this.defaultMessageStore.getMessageStoreConfig().getInSyncReplicas();
if (this.defaultMessageStore.getMessageStoreConfig().isEnableAutoInSyncReplicas()) {
needAckNums = Math.min(needAckNums, inSyncReplicas);
needAckNums = Math.max(needAckNums, this.defaultMessageStore.getMessageStoreConfig().getMinInSyncReplicas());
}
return needAckNums;
}- Method signature changes
No new request code. No request or method is changed.
Added parameters: totalReplicas, inSyncReplicas, minInSyncReplicas, enableAutoInSyncReplicas, haSlaveFallBehindMax.
Behavior change: In synchronous replication mode, parameters such as totalReplicas and inSyncReplicas need to be specified to confirm the number of copies to be ACK. In Broker Config, the haSlaveFallbehindMax parameter was canceled and replaced by haMaxGapNotInSync. The meaning and default values have been changed, as described above.
- CLI command changes
The client code and admin have not changed.
- Log format or content changes
No
- Are backward and forward compatibility taken into consideration?
Yes, RIP-34 takes compatibility into account and can achieve backward and forward compatibility. However, users need to set correct parameters to achieve correct backward compatibility. For example, if the user upgrades the original cluster to the RIP-34 version without modifying any parameters, the totalReplicas and inSyncReplicas are both set to 1 by default, and the replication will be degraded to asynchronous replication. If the behavior needs to be consistent with the previous behavior, You need to set both totalReplicas and inSyncReplicas to 2.
-
Are there deprecated APIs?
Nothing specific.
-
How do we do migration?
Set the correct parameters and upgrade normally.
We will implement the proposed changes by 1 phases.
- Complete quorum write
- Complete adaptive degradation
No other alternatives