RIP 44 Support DLedger Controller
- Current State: accept
- Authors: RongtongJin, ZhangHeng Huang
- Shepherds: duhengforever@apache.org, dongeforver@apache.org
- Mailing List discussion: dev@rocketmq.apache.org
- Pull Request: https://github.com/apache/rocketmq/pull/4484
- Released:
- Related Docs: English 中文版
-
Will we add a new module?
Yes, a new controller module will be added.
-
Will we add new APIs?
No additions or modifications to any client-level APIs
Admin tools add related new commands
There will be a new API for the internal interaction between broker and controller
-
Will we add a new feature?
Yes, dledger controller is a new feature.
- Are there any problems of our current project?
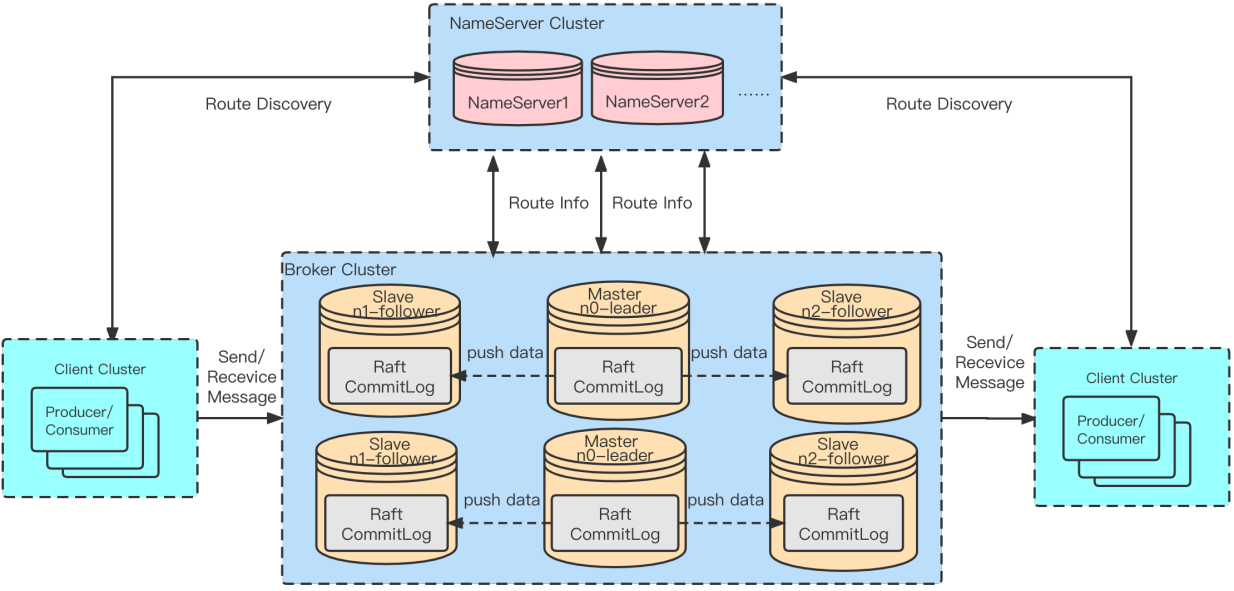
After the release of RocketMQ 4.5.0, the DLedger mode (raft) was introduced. The raft commitlog under this architecture is used to replace the original commitlog so that it has the ability to failover. However, there are some disadvantages going with this architecture due to the raft capability on replication, including:
-
To have failover ability, the number of replicas in the broker group must be 3 or more
-
Acks from replicas need to strictly follow the majority rule of the Raft protocol, that is, 3-replica architecture requires acks from 2 replicas to return, and 5-replica architecture requires acks from 3 to return
-
Since the store repository relies on OpenMessaging DLedger in DLedger mode, Native storage and replication capabilities of RocketMQ (such as transientStorePool and zero-copy capabilities) cannot be reused, and maintenance becomes difficult as well.
To handle those mentioned problems, RIP-44 want to support dledger controller. With this improvement, DLedger (Raft) capability will be abstracted onto the upper layer, becoming an optional and loosely coupled coordination component named DLedger Controller.
After the deployment of DLedger Controller, the master-slave architecture will also equip with failover capability. The DLedger Controller can optionally be embedded into the NameServer (the NameServer itself remains stateless and cannot provide electoral capabilities when the majority is down), or it can be deployed independently.
DLedger controller is an optional component that does not change the previous operation and maintenance mode. Compared with other components, its downtime will not affect online services. In addition, RIP-44 unifies the storage and replication of RocketMQ, resulting in lower maintenance costs and faster development iterations. In terms of compatibility, the master-slave architecture can upgrade without compatibility problems.
- What can we benefit from proposed changes?
RIP-44 enables RocketMQ to have the optional failover capability in the Master-Slave deployment and can utilize RocketMQ's native storage and replication capabilities, with consistent log data and no message loss.
- What problem is this proposal designed to solve?
This enables RocketMQ to have the optional failover capability in the Master-Slave deployment and can utilize RocketMQ's native storage and replication capabilities, with consistent log data and no message loss.
- What problem is this proposal NOT designed to solve?
The following are not designed to solve this RIP:
-
External coordination components such as ZooKeeper and ETCD are introduced to solve the failover problem
-
The master-slave election capability is mandatory
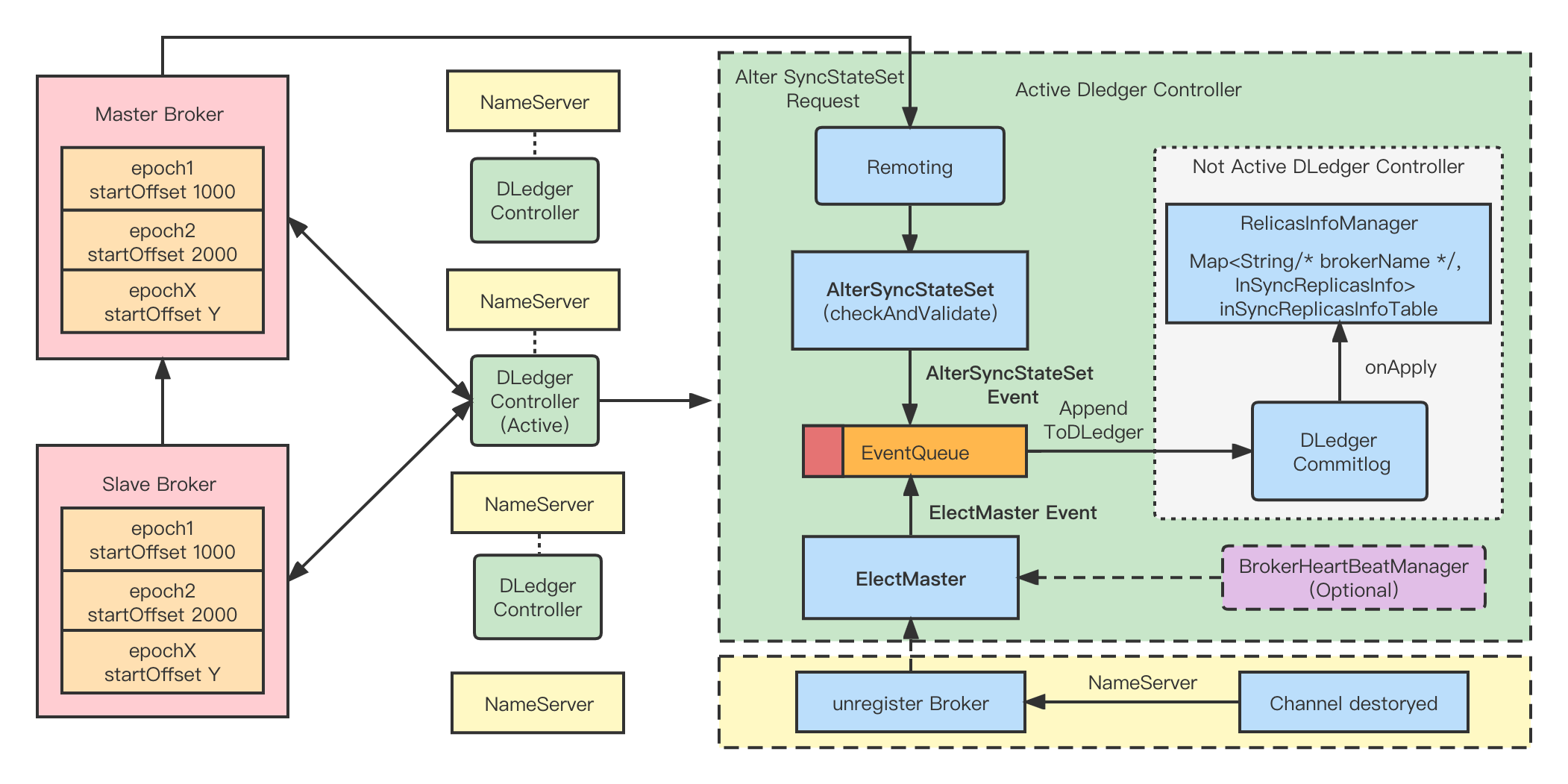
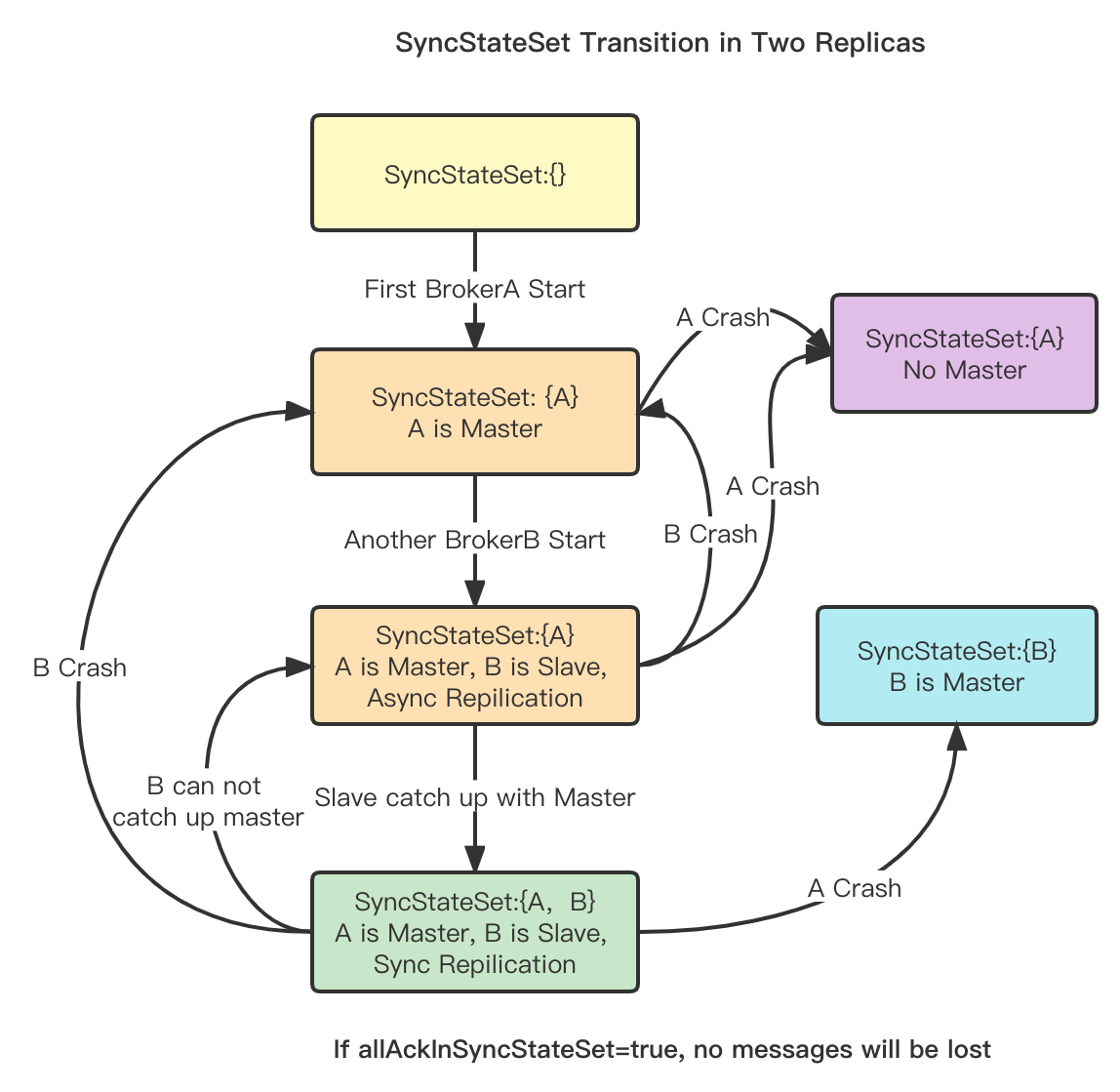
SyncStateSet: It mainly represents the replicas in a broker group that keep up with the master (including the master itself). The main criterion is the gap between the master and the slave. When the master goes offline we elect a new master from the SyncStateSet.
Active Controller: Use Raft capabilities to build DLedger controller that ensures the metadata consistency. Using Raft elections, an Active DLedger Controller will be elected as the active controller. The DLedger Controller can be embedded in the Nameserver and turned on by a switch ( And after the nameserver hangs up the majority, it only affects the failover ability, the original ability of the nameserver is still stateless). Additionally, DLedger Controller supports standalone deployment.
Alter SyncStateSet: The master broker will regularly detect whether the SyncStateSet needs to be expanded or reduced, and report the SyncStateSet information through the API. The DLedger Controller will maintain the SyncStateSet of the broker replica group with strong consistency.
Elect Master: Once the Master of the Broker's replica group is offline, the Active DLedger Controller is notified via heartbeat mechanisms (there are two of them, NameServer's lightweight heartbeat if embedded, or its own heartbeat module if deployed independently), Then calling the Elect Master API will re-select a master from the SyncStateSet, and send instructions to the Broker to complete the master-slave switch.
Replication: Broker's internal replication adds epoch and start offset, epoch represents the version, and start offset is the start physical offset from the version number. Data truncation after switching is completed with both epoch and start offset to ensure commitlog consistency.
We need a controller with strong metadata consistency to manage the SyncStateSet and switch the master when a broker's master broker goes offline. Currently DLedger, as a Raft Commitlog-based repository, fits the bill just fine.
DLedger Controller has the following two deployment scenarios:
- Embedded NameServer: If you want to ensure the high availability of the election module, you must start at least three NameServers, turn on the Controller switch in the NameServer to start the plug-in of the DLedger Controller. The Controller relies on the DLedger capability to ensure strong consistency. In addition, DLedger Controller is not as complicated as zookeeper and etcd. It tries to simplify external API, has no monitoring mechanism, and relies on polling and notification instead.
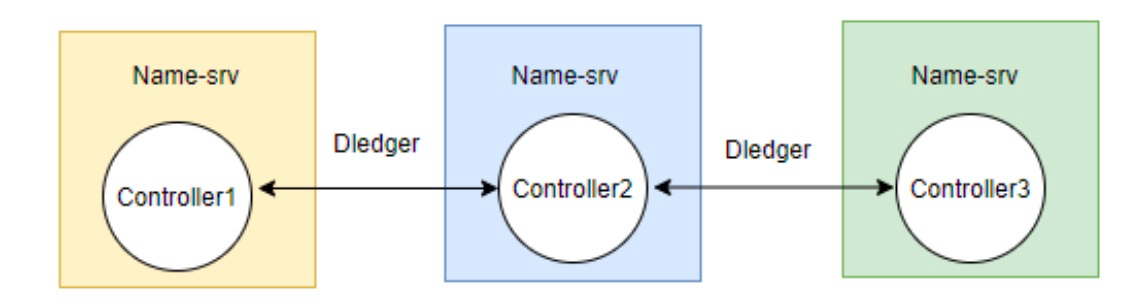
Independent deployment: DLedger Controller also supports independent deployment
The SyncStateSet list represents a list of synchronized replicas. It mainly represents the number of Slave replicas that follow the Master plus the Master in a group of broker replicas. The main criterion is the difference between Master and Slave. When the Master goes offline, we will select a new Master from the SyncStateSet.
Changes to the SyncStateSet are primarily initiated by the Master Broker. The Master Broker completes SyncStateSet's Shrink and Expand requests through scheduled task judgments and synchronization processes, and initiates an Alter SyncStateSet request to the controller. After the controller application is successful, update your local cache SyncStateSet.
- Shrink SyncStateSet
Shrink SyncStateSet, refers to the removal of those replicas that are too far from the Master in the SyncStateSet replica set. The gap here is mainly in several aspects:
- Whether to establish a connection with the Master Broker, if disconnected, remove the Slave from the SyncStateSet (no connection may be a network problem, heartbeat timeout, etc.).
- The haMaxTimeSlaveNotCatchUp parameter is added, and HaConnection records the timestamp lastCaughtUpTimeMs of the last time the Slave catches up with the Master. The meaning of the timestamp is: every time the Master sends data (transferData) to the Slave, record its current MaxOffset as lastMasterMaxOffset and the current timestamp lastTransferTimeMs. If slaveAckOffset>=lastMasterMaxOffset is reported in ReadSocketService, lastCaughtUpTimeMs is updated to lastTransferTimeMs.
- The scheduled task scans each connection, if (cur_time - connection.lastCaughtUpTimeMs) > haMaxTimeSlaveNotCatchUp, the Slave is Out-of-sync.
- Finally, if it is determined that a Slave is out-of-sync, the Master needs to update the SyncStateSet to the Controller Alter in time. If the update is successful, it will be applied locally.

- Expand SyncStateSet
Similarly, if a Slave replica catches up with the Master, the Master needs to update the Controller Alter SyncStateSet in a timely manner. If the update succeeds, it will be applied locally. The terms of joining SyncStateSet are SlaveAckOffset >= ConfirmOffset (the concept of ConfirmOffset is described below as the minimum MaxOffset for all current SyncStateSet replicas).
The Controller builds consistent metadata internally based on Dledger, and provides API for modifying and reading metadata externally. The main external APIs are as follows:
public interface Controller {
/**
* Alter SyncStateSet of broker replicas.
*
* @param request AlterSyncStateSetRequestHeader
* @return RemotingCommand(AlterSyncStateSetResponseHeader)
*/
CompletableFuture<RemotingCommand> alterSyncStateSet(
final AlterSyncStateSetRequestHeader request, final SyncStateSet syncStateSet);
/**
* Elect new master for a broker.
*
* @param request ElectMasterRequest
* @return RemotingCommand(ElectMasterResponseHeader)
*/
CompletableFuture<RemotingCommand> electMaster(final ElectMasterRequestHeader request);
/**
* Register api when a replicas of a broker startup.
*
* @param request RegisterBrokerRequest
* @return RemotingCommand(RegisterBrokerResponseHeader)
*/
CompletableFuture<RemotingCommand> registerBroker(final BrokerRegisterRequestHeader request);
/**
* Get the Replica Info for a target broker.
*
* @param request GetRouteInfoRequest
* @return RemotingCommand(GetReplicaInfoResponseHeader)
*/
CompletableFuture<RemotingCommand> getReplicaInfo(final GetReplicaInfoRequestHeader request);
/**
* Get Metadata of controller
*
* @return RemotingCommand(GetControllerMetadataResponseHeader)
*/
RemotingCommand getControllerMetadata();
}AlterSyncStateSet
First of all, the AlterSyncStateSet must be initiated by the master of a broker. The slave has no right to initiate the request, and the request will report the latest SyncStateSet of the group of brokers to the controller. The request processing does a pre-check first.
Pre-check logic:
- Compare whether the Broker that initiated the request is the Master, Alter SyncStateSet can only be initiated by the Master Broker
- Compared to SyncStateSet epoch, it may be stale AlterSyncStateSet request
- Check the correctness of the SyncStateSet, that is, whether the Brokers in the SyncStateSet are all in the Alive broker (through a lightweight heartbeat mechanism)
- The new SyncStateSet must contain the current leader because the Master cannot be removed from the SyncStateSet
If the check passes, we can generate an Alter SyncStateSet event, initiate consensus request through Dledger, and finally modify the in-memory SyncStateSet.
Elect Master
ELectMaster mainly selects a new Master from the SyncStateSet when the Master of a Broker replica group is offline or inaccessible. This event is initiated by the Controller itself.
The heartbeat mechanism is mainly used here. The Broker will report the heartbeat to the Controller on a regular basis, and the Controller will also regularly scan the timeout Broker (scanNotActiveBroker). If a Broker's heartbeat times out, the Controller will determine whether it is a Master (brokerId = 0) and if it is a Master, it will initiate ElectMaster to elect a new Broker Master.
The method of electing a Master is relatively simple. We only need to select a surviving copy (the heartbeat has not timed out) from the SyncStateSet list corresponding to the group of Brokers to become the new Master, and then elect to generate an ElectMaster event. After passing the DLedger consensus apply it to the memory metadata and notify the corresponding Broker replica group of the result (Broker itself also has a polling mechanism to obtain the Master information (getReplicaInfo) of its own replica group for further assurance to prevent notification loss).
In addition, the controller adds the enableUncleanMasterElect parameter. At this time, if the SyncStateSet does not have a copy that meets the requirements, it can be selected from all the current surviving copies, but a large number of messages may be lost.
RegisterBroker
RegisterBroker is first called when the Broker comes online, making a registration request to the Controller.
The Controller returns the brokerId and Master of the replicas. That is, in Controller mode, brokerId are determined and assigned by the Controller.
- Assignment of brokerId
When a broker goes online for the first time, the metadata cannot find BrokerId and initiates the ApplyBrokerId event proposal, Assign a brokerId to the Broker (brokerId is applied if the Broker is not Master or 0 otherwise).
- Master-slave relationship is determined when online
In addition when the broker first goes online, there is no master. At this time, the first called broker will try to become the master, form the ElectMasterEvent event and submit the proposal, and the first Broker in the replica group that successfully applies the ElectMasterEvent event log will become the Master, and form only its own SyncStateSet.
GetReplicaInfo
This API is mainly used by the Broker to regularly pull the latest metadata information from the Controller. In order to prevent the loss of notifications after the master election, the broker will also call this method regularly, so as to know who is the master of this replica group.
GetControllerMetadata
This API mainly obtains the active controller (the Leader of the Controller), and returns the IP address of the active controller, Among the above APIs, only the GetControllerMetadata API can be called by all controllers (leader controller+follower controller), and other APIs can only be called by the active controller.
Consistent metadata is finally constructed by applying the log events of Commitlog in DLedger. The data structure is as follows:
private final Map<String/* brokerName */, BrokerInfo> replicaInfoTable;
private final Map<String/* brokerName */, SyncStateInfo> syncStateSetInfoTable;BrokerInfo data structure
/**
* Broker info, mapping from brokerAddress to {brokerId, brokerHaAddress}.
*/
public class BrokerInfo {
private final String clusterName;
private final String brokerName;
// Start from 1
private final AtomicLong brokerIdCount;
private final HashMap<String/*Address*/, Long/*brokerId*/> brokerIdTable;
}SyncSateInfo data structure
/**
* Manages the master and syncStateSet of broker replicas.
*/
public class SyncStateInfo {
private final String clusterName;
private final String brokerName;
private Set<String/*Address*/> syncStateSet;
private int syncStateSetEpoch;
private String masterAddress;
private int masterEpoch;
}Events here can also refer to log types, and the state machine will eventually apply the events in the DLedger Commitlog to build consistent metadata.
AlterSyncStateSet Event
It is initiated by the AlterInSyncReplicas API after verification, and the corresponding SyncStateInfo data in syncStateSetInfoTable is modified after the state machine is applied.
ElectMaster Event
It is initiated by the ElectMaster API and RegisterBroker API after passing the verification. After the state machine log is applied, the corresponding SyncStateInfo data in the syncStateSetInfoTable is modified, masterEpoch = masterEpoch+1, the master is changed to elect a broker, and the SyncStateSet is changed to only the set of elected brokers.
ApplyBrokerId Event
Initiated by the RegisterBroker API. When the broker queries the replica group information, it is initiated when the brokerId cannot be found. When the state machine applies the log, it will first check whether it already exists. If it already exists, it will not apply again.
On the basis of the original replication, multiple stages are extended to complete the necessary data truncation and postback. The replication process is carried out in multiple stages, and different tasks are completed in HANDSHAKE (the ordinary basic version basically does nothing, and the election version completes the comparison and truncation of epoch and startOffset).
public enum HAConnectionState {
/**
* Ready to start connection.
*/
READY,
/**
* CommitLog consistency checking.
*/
HANDSHAKE,
/**
* Synchronizing data.
*/
TRANSFER,
/**
* Temporarily stop transferring.
*/
SUSPEND,
/**
* Connection shutdown.
*/
SHUTDOWN,
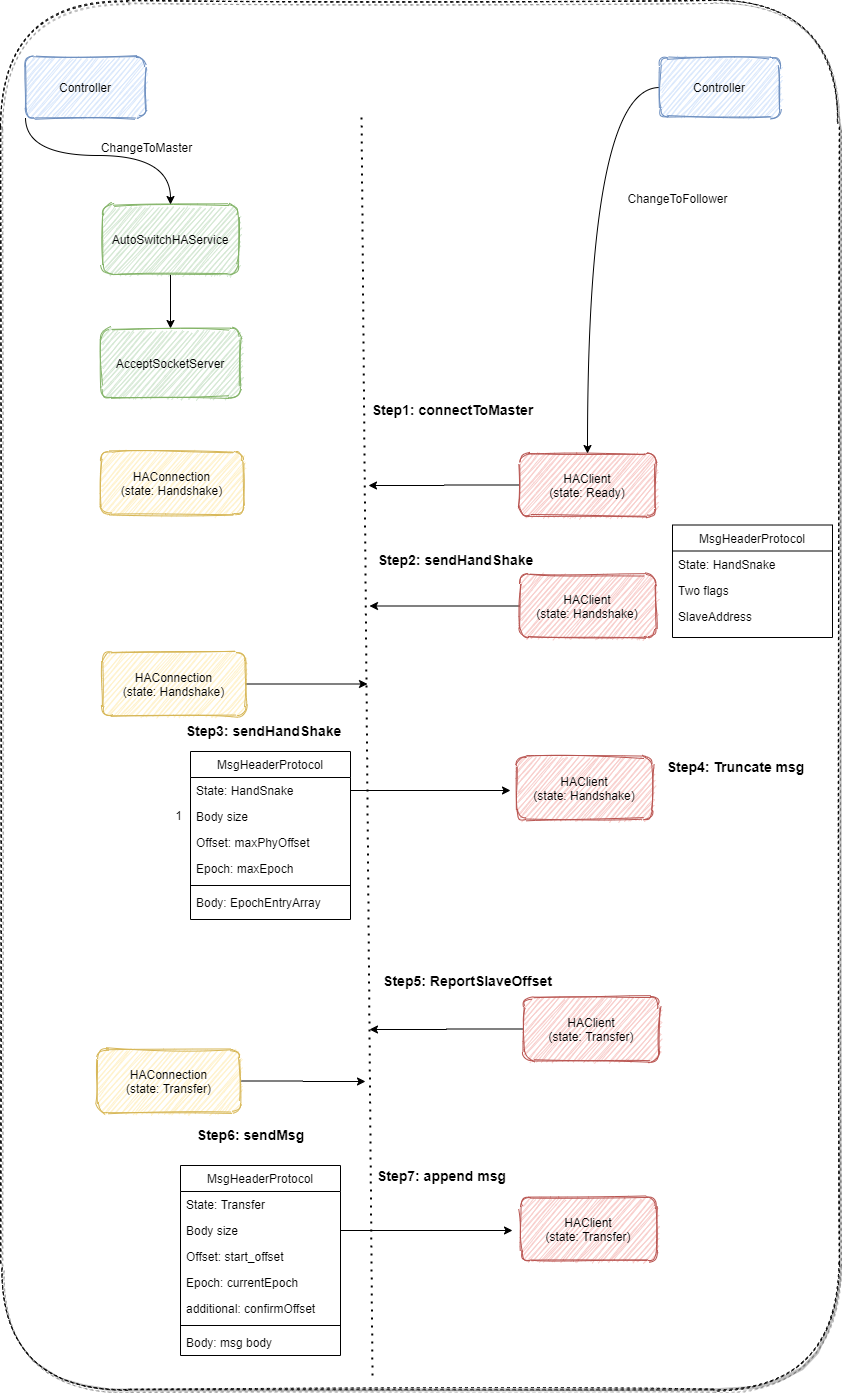
}As shown in the figure below, it is the overall process of log replication:
- Master and Slave respectively accept commands from Controller and execute ChangeToXXX
- Master starts AutoSwitchHAService, listens for connections, and creates AutoSwitchHAConnection
- Slave starts AutoSwitchHAClient, and in Ready stage, connects to Master (connectToMaster)
- After the connection is completed, AutoSwitchHAClient enters the HandShake phase, and sends a Handshake packet, including some status bits and the address of the Slave.
- AutoSwitchHAConnection echoes the handshake packet, which includes its local EpochEntry array.
- AutoSwitchHAClient compares the received MasterEpochEntryArray with the local EpochEntryArray, and performs the corresponding log phase process, so as to be consistent with the Master.
- After the truncation is completed, AutoSwitchHAClient enters the Transfer phase and continuously reports slaveOffset to AutoSwitchHAConnection.
- AutoSwitchHAConnection sends log packets to enter the log replication process.
First, add MasterEpoch, which represents the version number of Master, analogous to Term in Raft.
The MasterEpoch is specified by the Controller to ensure that there is only one MasterEpoch at the same time, that is, only one Master exists. Whenever a new Master is elected, the local maximum MaxOffset will be used as the startOffset of the MasterEpoch.
In addition, a new epochFile is added, stored in the ~/store folder, which stores each epoch and its corresponding log start sequence startOffset. (Considering the importance of the file, it is not stored in the checkpoint file)
The algorithm is described as follows:
In order to facilitate the understanding of the algorithm, the concept of endOffset is added here. endOffset is actually the startOffset of the next epoch (the maximum position if there is no next epoch), and does not need to be stored in the actual implementation.
Slave compares the obtained Master <startoffset, endoffset>. If the startoffset is equal, the epoch is valid. The truncation point is the smaller endoffset of the two. After truncation, it corrects its own <epoch, startoffset> information and enters the transfer stage; if Not equal, find the previous epoch of the slave, and continue to walk 1 until the truncation site is found.
slave:TreeMap<Epoch, Pair<startOffset,endOffset>> epochMap;
Iterator iterator = epochMap.descendingMap().entrySet().iterator();
truncateOffset = -1;
while (iterator.hasNext()) {
Map.Entry<Epoch, Pair<startOffset,endOffset>> curEntry = iterator.next();
Pair<startOffset,endOffset> masterOffset = findMasterOffsetByEpoch(curEntry.getKey());
if(masterOffset!=null && curEntry.getKey().getObejct1() == masterOffset.getObejct1()) {
truncateOffset = Math.min(curEntry.getKey().getObejct2(), masterOffset.getObejct2());
break;
}
}If the truncateOffset is not found, such as the Master file has expired and deleted, manual processing is required. When truncating, ensure the consistency of consume queue and commitlog, and consume queue will also be truncated.
Algorithm Consistency Proof:
-
The epoch is specified by the Controller. The consensus protocol ensures that all epochs assigned to the broker are unique and increasing. During each epoch, the controller assigns only one broker to be the master. And each broker becomes Master and truncates the commitlog to the boundary of the last message.
-
For each log (epoch, offset), only one master is responsible for accepting the log, and the slave will only replicate the log from the same master. So for the same (epoch, offset), it will represent the same log entry.
-
Every time the Slave truncates the log according to the above algorithm, it is guaranteed that the log before truncateOffset is consistent with the Master.
Truncation example analysis:



(1) The endoffset of epoch0 is truncated to the minimum of 900. When unCleanMasterElect=false, allAckInSyncStateSet=true, only the messages within 900 are committed messages.
(2) A loses 900-1000 messages due to asynchronous flush. Finally, the endoffset of epoch0 is truncated to 900, which is the minimum of the two. A will continue to copy B's messages, and no messages will be lost.
(3) The endoffset of epoch1 is truncated to the minimum of 1200, which does not actually need to be truncated.
(4) The endoffset of epoch0 is truncated to the minimum of 900.
(5) Both B and C are truncated to 800 of epoch1.
(6) The endoffset of epoch0 is truncated to the minimum of 1000.
The epoch file stores Map<epoch, startOffset> information, which needs to be updated in time, especially since the slave and master are stream-based replication, the slave cannot perceive the epoch change during the master-standby replication process (because the message will not be parsed). In addition, the map in the epoch file needs to be corrected in time, mainly in the following scenarios:
- When preparing handshake, correct after truncation, and correct your map to the map before the master truncation point
- Correction of exceeding the valid offset when Recovering
- When the file is deleted, if the endOffset of a certain epoch is exceeded, the epoch is deleted.
In order to solve the problem that the slave based on stream replication cannot perceive the change of epoch, the offset field will be added to the header of the transfer phase. The specific process is as follows:
Each time a batch of messages is sent in WriteSocketService, a Header is sent at the same time:
/**
* Header protocol in syncing msg from master.
* current state + body size + offset + epoch +
* epochStartOffset + additionalInfo(confirmOffset).
*/
public static final int MSG_HEADER_SIZE = 4 + 4 + 8 + 4 + 8 + 8;Among them, epoch represents the version number of all messages in this data stream sent by the master, and epochStartOffset represents the startOffset of the epoch. When the master transmits the log, it is guaranteed that a batch sent at a time is in the same epoch, and cannot span multiple epochs. Two new variables can be added to WriteSocketService:
- currentTransferEpoch: Indicates which epoch the current WriteSocketService.nextTransferFromWhere corresponds to
- currentTransferEpochEndOffset: corresponds to the end offset of currentTransferEpoch. If currentTransferEpoch == current maximum epoch, then currentTransferEpochEndOffset= -1, indicating no bound.
- When WriteSocketService transmits the next batch of logs (assuming the total size of this batch of logs is size), if it finds that nextTransferFromWhere + size > currentTransferEpochEndOffset, it will selectMappedBufferResult limit to currentTransferEpochEndOffset.
- Finally, modify currentTransferEpoch and currentTransferEpochEndOffset to the next epoch. Correspondingly, when Slave accepts the log, if the epoch change is found from the header, it will be recorded in the local epoch file.
Since truncation occurs in the algorithm if the original commitlog. getMaxOffset is used as the endpoint of reput, two consumer group will subscribe to the same topic, one will receive the truncated message, and the other will not receive the truncated message after the master/slave switch. A Read uncommitted condition occurs. ConfirmOffset is a new confirmOffset concept. Consume queue is dispatch only to confirmOffset to prevent messages that might be truncated from being read.
Computationally, the Master confirmOffset is the smallest MaxOffset point in all SyncStateSet replicas. The confirmOffset of the Slave is determined by two values. One is the Header that transmits the Master's current confirmOffset when the Master transmits, and the other is the current maximum confirmOffset. The minimum of the two values is taken.
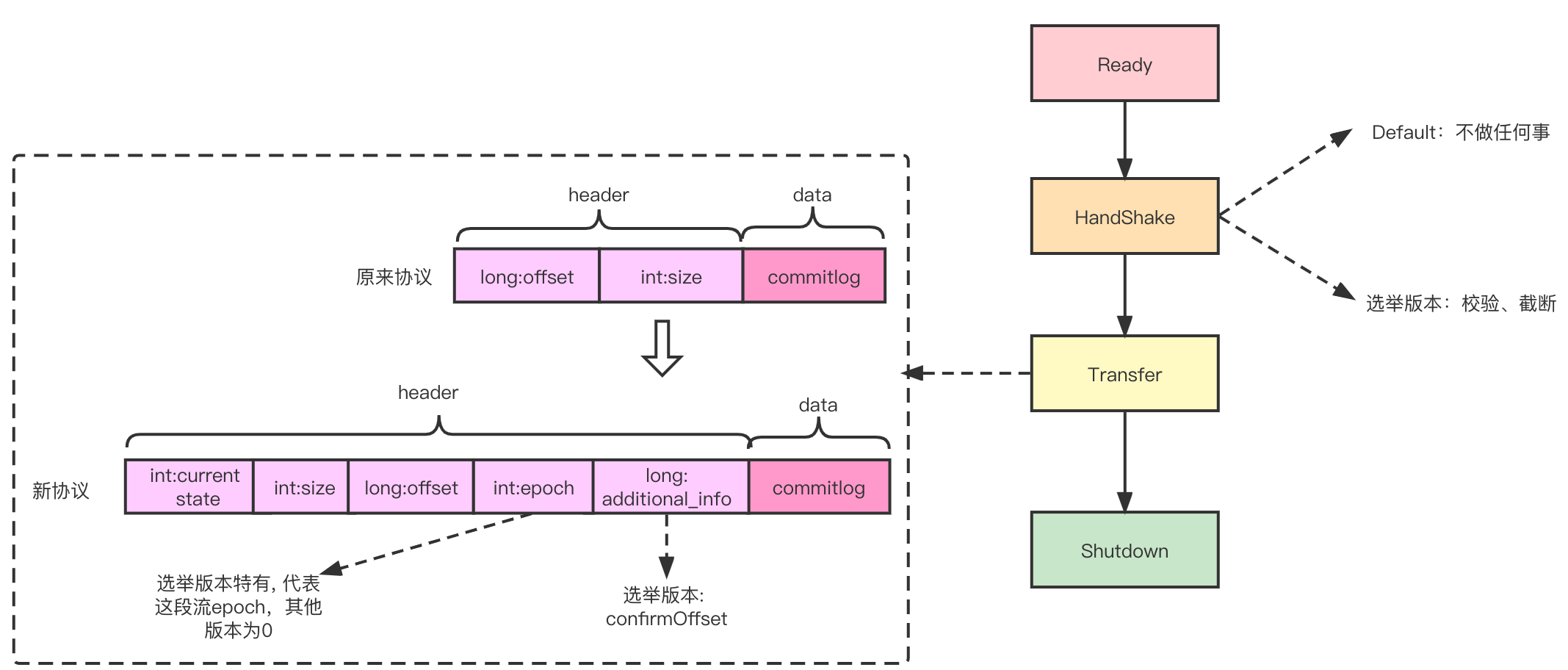
Due to the time difference between reports, the Master elected from SyncStateSet may still lose messages, so it needs to be used together with RIP-34. For example, if inSyncReplicas=2 (synchronous replication) in the case of two replicas, the Master elected in SyncStateSet after it hangs up must include all committed messages, and no messages will be lost. For example, if inSyncReplicas=2 under three replicas, after the Master hangs up, at least one of them will keep up with the Master replica. If the Slave that chooses to keep up becomes the master, no messages will be lost.
In addition, the allAckInSyncStateSet parameter is added. This parameter requires that all replicas in SyncStateSet must be acked before returning to the client. Enabling this parameter can ensure that no messages are lost (when allAckInSyncStateSet is true, inSyncReplicas will be invalid).
The implementation must ensure that the new SyncStateSet will be applied locally after the new SyncStateSet is successfully updated to the Controller.
Explain:
Assuming that there are two replicas of A and B, A is the Master and B is the Slave. At the beginning, the SyncStateSet is {A, B}. After B goes down, A applies to the Controller for a SyncStateSet change. Only when the Controller confirms that the update is successful, A will local SyncStateSet be updated to {A} (that is, the message after the update is successful will fail to be sent), which ensures that after allAckInSyncStateSet is enabled, the replica in SyncStateSet must have all committed messages, that is, messages will not be lost.
When the number of brokers in the SyncStateSet is less than minInSyncReplicas, the message will fail to send.
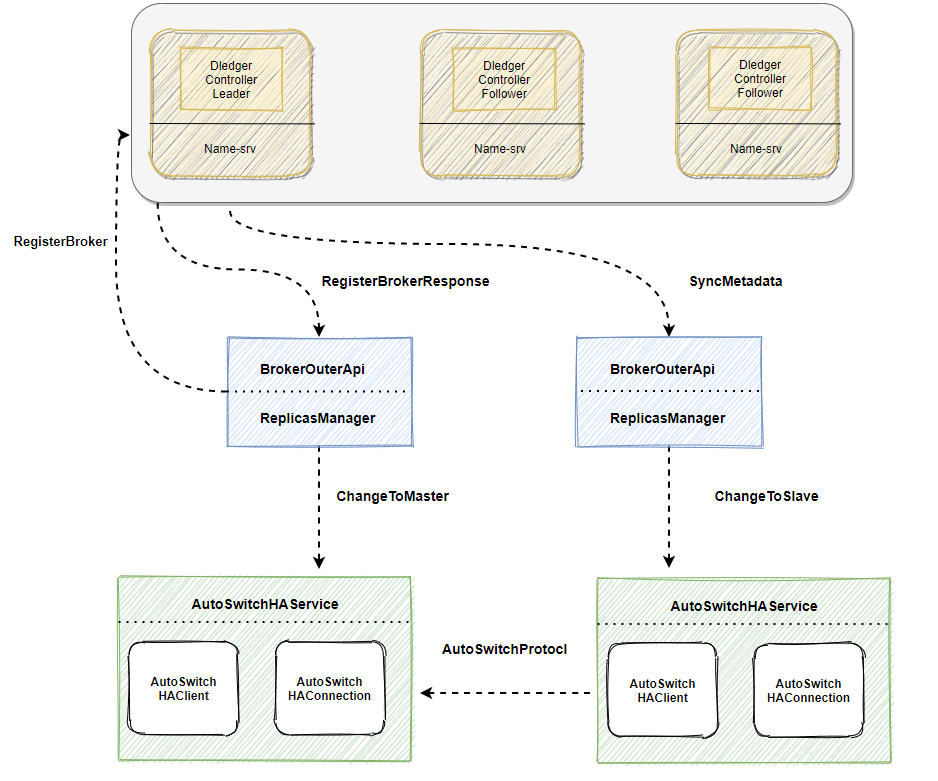
The figure shows the interaction process between broker and controller:
- The main logic for the interaction between the Broker and the Controller is in the component ReplicasManager
- When the broker goes online, ReplicasManager will initiate a registration request through RegisterBrokerToController (if the brokerId or the master-standby relationship cannot be obtained, the request will be made), and obtain the BrokerId and MasterAddress
- Next, ReplicasManager calls the API of AutoSwitchHAService and executes the ChangeToxxx process
- AutoSwitchHAService operates log truncation and replication according to the replication process described above
The broker side needs a complete online process.
Add the controllerAddress parameter, which is mainly used to configure the IP list of the Controller. Before the Broker is officially registered with the Namesrv, it will first register with the Controller, obtain the master-slave relationship and the brokerId (determine whether it is the master or the slave and the brokerId), and then register with the Nameserver.
The broker will obtain the IP of the active controller node from any controller (the background will also periodically obtain and update the IP of the active controller node), and then access the active controller.
In the election mode, the parameters brokerRole and brokerId are invalid, and finally the controller decides the master/slave relationship.
The master-slave relationship is determined after the initial launch: if there is no SyncStateSet of the broker group, the first one in the broker group to initiate a consensus request to the active controller is the master (composes only its own SyncStateSet, due to the log and consensus protocol, even if multiple brokers There is only one Master when it is initiated), and the rest are reserved. The allocation of brokerId increases from 1, that is, each broker is numbered from 1, the master's brokerId will become 0, and the original number will be restored after the master becomes a slave.
The master-slave relationship is determined after going online again: subject to SyncStateSet
Regularly obtain the master-slave relationship: Each broker will periodically poll the Controller to obtain master-slave information (getReplicationInfo), even if it updates its own role (to prevent notification loss).
It is basically the same as the current switching process of DLedger mode.
- Turn on/off some scanning threads for secondary messages (timing, transactions, POP ACK, etc.)
- Modify brokerId and brokerRole
- Re-register with Nameserver
If you switch to the master, you also need to wait for consumeQueue dispatch, topicQueueTable recover, etc.
We also introduced a new role for the Broker: Async Learner, similar to the Learner role in Raft, which can be turned on with the parameter isAsyncLearner.
If the Broker enables the role of AsyncLearner, it will notify the Master through AutoSwitchHA Protocl during the log replication process. In the subsequent log replication, the Master will not add AsyncLearner to SyncStateSet, which ensures that there is no need to wait for AsyncLearner to reply Ack (asynchronous replication), At the same time it will not join the election process (because it is not in the SyncStateSet).
Applicable scenarios: Asynchronous replication in different data centers.
- Method signature/behavior changes
New RequestCode
// Alter syncStateSet
public static final int CONTROLLER_ALTER_SYNC_STATE_SET = 1001;
// Elect master
public static final int CONTROLLER_ELECT_MASTER = 1002;
// Register broker
public static final int CONTROLLER_REGISTER_BROKER = 1003;
// Get replica info
public static final int CONTROLLER_GET_REPLICA_INFO = 1004;
// Get controller metadata
public static final int CONTROLLER_GET_METADATA_INFO = 1005;
// Get syncStateData (used for adminTool)
public static final int CONTROLLER_GET_SYNC_STATE_DATA = 1006;
// Get brokerEpoch (used for adminTool)
public static final int GET_BROKER_EPOCH_CACHE = 1007;
// Notify broker role changed
public static final int NOTIFY_BROKER_ROLE_CHANGED = 1008;Controller接口如下
/**
* The api for controller
*/
public interface Controller {
/**
* Startup controller
*/
void startup();
/**
* Shutdown controller
*/
void shutdown();
/**
* Start scheduling controller events, this function only will be triggered when the controller becomes leader.
*/
void startScheduling();
/**
* Stop scheduling controller events, this function only will be triggered when the controller shutdown leaderShip.
*/
void stopScheduling();
/**
* Whether this controller is in leader state.
*/
boolean isLeaderState();
/**
* Alter SyncStateSet of broker replicas.
*
* @param request AlterSyncStateSetRequestHeader
* @return RemotingCommand(AlterSyncStateSetResponseHeader)
*/
CompletableFuture<RemotingCommand> alterSyncStateSet(
final AlterSyncStateSetRequestHeader request, final SyncStateSet syncStateSet);
/**
* Elect new master for a broker.
*
* @param request ElectMasterRequest
* @return RemotingCommand(ElectMasterResponseHeader)
*/
CompletableFuture<RemotingCommand> electMaster(final ElectMasterRequestHeader request);
/**
* Register api when a replicas of a broker startup.
*
* @param request RegisterBrokerRequest
* @return RemotingCommand(RegisterBrokerResponseHeader)
*/
CompletableFuture<RemotingCommand> registerBroker(final BrokerRegisterRequestHeader request);
/**
* Get the Replica Info for a target broker.
*
* @param request GetRouteInfoRequest
* @return RemotingCommand(GetReplicaInfoResponseHeader)
*/
CompletableFuture<RemotingCommand> getReplicaInfo(final GetReplicaInfoRequestHeader request);
/**
* Get Metadata of controller
*
* @return RemotingCommand(GetControllerMetadataResponseHeader)
*/
RemotingCommand getControllerMetadata();
/**
* Get inSyncStateData for target brokers, this api is used for admin tools.
*/
CompletableFuture<RemotingCommand> getSyncStateData(final List<String> brokerNames);
/**
* Get the remotingServer used by the controller, the upper layer will reuse this remotingServer.
*/
RemotingServer getRemotingServer();
}- CLI command changes
Add two CLI commands
- GetBrokerEpochCommand
sh bin/mqadmin getSyncStateSet
usage: mqadmin getSyncStateSet -a <arg> [-b <arg>] [-c <arg>] [-h] [-i <arg>] [-n <arg>]
-a,--controllerAddress <arg> the address of controller
-b,--brokerName <arg> which broker to fetch
-c,--clusterName <arg> which cluster
-h,--help Print help
-i,--interval <arg> the interval(second) of get info
-n,--namesrvAddr <arg> Name server address list, eg:'192.168.0.1:9876;192.168.0.2:9876'Used to get the Epoch information of a Broker
- GetSyncStateSetSubCommand
sh bin/mqadmin getBrokerEpoch
usage: mqadmin getBrokerEpoch [-b <arg>] [-c <arg>] [-h] [-i <arg>] [-n <arg>]
-b,--brokerName <arg> which broker to fetch
-c,--clusterName <arg> which cluster
-h,--help Print help
-i,--interval <arg> the interval(second) of get info
-n,--namesrvAddr <arg> Name server address list, eg: '192.168.0.1:9876;192.168.0.2:9876'Used to get the SyncStateSet information of a Broker group or cluster

- Log format or content changes
The controller component will add a log configuration file
Add the following parameters
Controller main parameters:
- enableControllerInNamesrv: Whether to enable the controller in the Nameserver, the default is false. If it is deployed for the embedded Nameserver, it needs to be set to true in the NameServer configuration file
- controllerDLegerGroup: The name of the DLedger Raft Group, which can be consistent with the same DLedger Raft Group.
- controllerDLegerPeers: Port information of each node in the DLedger Group, the configuration of each node in the same Group must be consistent.
- controllerDLegerSelfId: Node id, which must belong to one of controllerDLegerPeers; each node within the same Group must be unique.
- controllerStorePath: The controller log storage location. The controller is stateful. When the controller restarts or crashes, it needs to rely on the log to recover data. This directory is very important and cannot be easily deleted.
- enableElectUncleanMaster: Whether the Master can be elected from outside the SyncStateSet. If true, the copy with the data behind may be selected as the Master and messages will be lost. The default is false.
- notifyBrokerRoleChanged: Whether to actively notify when the role on the broker replica group changes, the default is true.
Broker's new parameters:
- enableControllerMode: The master switch of the Broker controller mode, only if the value is true, the controller mode will be turned on. Defaults to false.
- controllerAddr: The address of the controller. Multiple controllers are separated by semicolons. E.g controllerAddr = 127.0.0.1:9877;127.0.0.1:9878;127.0.0.1:9879
- controllerDeployedStandAlone: Whether the controller is deployed independently, if the controller is deployed independently, it is true, and if it is deployed with an embedded Nameserver, it is false. Defaults to false.
- syncBrokerMetadataPeriod: The time interval for synchronizing Broker replica information to the controller. Default 5000 (5s).
- checkSyncStateSetPeriod: The time interval for checking SyncStateSet, checking SyncStateSet may shrink SyncState. Default 5000 (5s).
- syncControllerMetadataPeriod: The time interval for synchronizing the controller metadata, mainly to obtain the address of the active controller. Default 10000 (10s).
- haMaxTimeSlaveNotCatchup: Indicates that the slave does not keep up with the maximum time interval of the Master. If the slave in the SyncStateSet exceeds the time interval, it will be removed from the SyncStateSet. Default is 15000 (15s).
- storePathEpochFile: The location to store the epoch file. The epoch file is very important and cannot be deleted at will. The default is in the store directory.
- allAckInSyncStateSet: If the value is true, a message needs to be copied to each copy in the SyncStateSet to return success to the client, which can ensure that messages are not lost. Defaults to false.
- syncFromLastFile: If the slave is started from an empty disk, whether to copy from the last file. Defaults to false.
- asyncLearner: If the value is true, the replica will not enter the SyncStateSet, that is, it will not be elected as the Master, but will always be used as a learner copy for asynchronous replication. Defaults to false.
This mode does not add or modify any client-level APIs, and there is no client-side compatibility issue.
No modification has been made to the capabilities of the Nameserver itself, and there is no compatibility problem with the Nameserver. If enableControllerInNamesrv is enabled and the controller parameters are configured correctly, the controller function is enabled.
If the Broker sets enableControllerMode=false, it will still run in the previous way. If enableControllerMode=true is set, the controller needs to be deployed and the parameters are configured correctly to run normally.
The specific behavior is shown in the following table:
| Old nameserver | Old nameserver + Deploy controllers independently | New nameserver enables controller | New nameserver disable controller | |
|---|---|---|---|---|
| Old broker | Normal running, cannot failover | Normal running, cannot failover | Normal running, cannot failover | Normal running, cannot failover |
| New broker enable controller mode | Unable to go online normally | Normal running, can failover | Normal running, can failover | Unable to go online normally |
| New broker disable controller mode | Normal running, cannot failover | Normal running, cannot failover | Normal running, cannot failover | Normal running, cannot failover |
- Are there deprecated APIs?
No
- How do we do migration?
It can be seen from the above compatibility statement that the NameServer can be upgraded normally without compatibility issues. If you do not want to upgrade the Nameserver, you can deploy the Controller component independently to obtain the switching capability.
For the Broker upgrade, there are two situations:
(1) Master-Slave deployment is upgraded to Controller switching architecture
You can upgrade with data directly. For each group of Brokers, shut down the active and standby Brokers to ensure that the Commitlogs of the active and standby are aligned (you can disable writing to the group of Brokers for a period of time before upgrading, or copy store data to ensure consistency), upgrade the package then restart it.
(2) The original DLedger mode is upgraded to the Controller switching architecture
Due to the difference between the original DLedger mode message data format and the data format in Master-Slave, no upgrade path with data is provided. In the case of deploying multiple groups of Brokers, you can disable writing to a certain group of brokers for a period of time (as long as you confirm that all the existing messages are consumed, for example, it is determined according to the storage time of the messages), and then clear the store directory except config/topics.json, and subscriptionGroup.json (retaining the metadata of the topic and subscription relationship), and then perform an empty disk upgrade.
Introduce external coordination components such as zookeeper, etcd to achieve switching capabilities
Pros:
There is no need to write part of the code of the controller, and the switching capability can be quickly realized
Cons:
Additional operation and maintenance costs are incurred after the introduction of external components
The DLedger model has been used in the community for many years. DLedger itself is a Raft-based Commitlog repository. On this basis, a consensus component of fault-tolerant consensus can be built. Through deep integration with RocketMQ, the DLedger Controller can become very lightweight, and It is loosely coupled and can be optionally deployed or embedded in NameServer. This component does not have too much operation and maintenance burden. Therefore there is no need to introduce additional external coordination components.